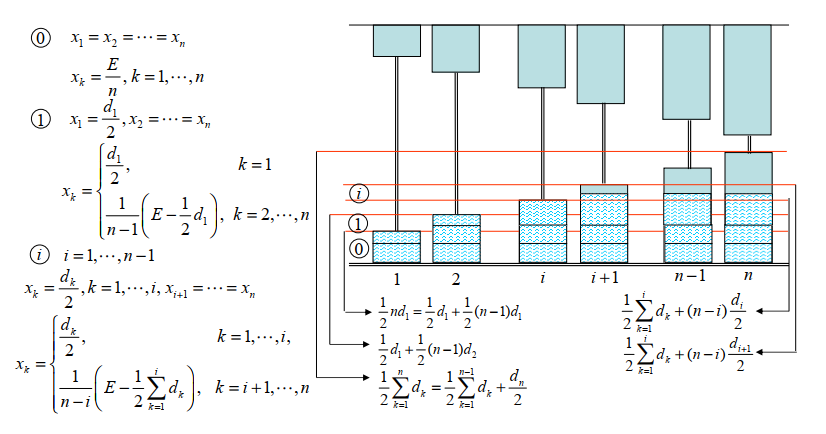
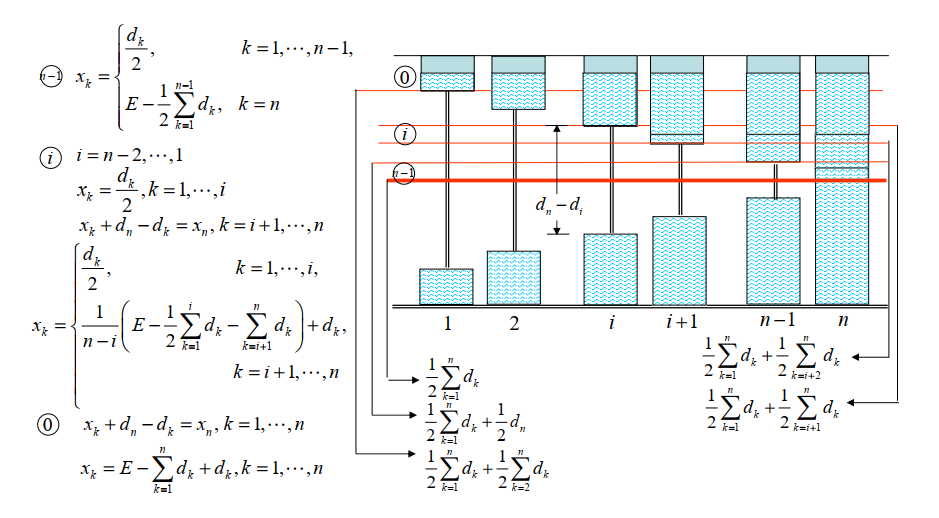
数学建模
01 秘密共享
数学建模的第一个例子
问题背景
11名科学家正在进行一个秘密项目。他们希望把文件锁在一个柜子里,只有当6名或更多的科学家在场时,柜子才能被打开。问:需要的最小锁数是多少?每个科学家必须携带的最小钥匙数量是多少?
秘密共享-组合数学
首先,你想到了高中学过的组合数学!你决定先从基数比较少的情况入手,即只有5名科学家的情况。
特殊情况
"问题背景"
5人在保险柜内存放秘密文件,只有3人及以上在场才能打开,至少几把锁?每个人至少要带多少钥匙?
"分析"
-
两个人过来的时候,必然至少有一把锁不能被打开。
- 因为我们此时考虑最少锁的情况,所以取任意二人组合不能打开锁的数量为 1。
- 所以每把锁与一对(没有钥匙的)两人组合对应,要有C52=10把锁
- 为什么不能是两对?
- ——因为两对都不能打开同一把锁的情况下,三个人过来的时候,就不能打开保险柜了。
-
三个人过来的时候,必然能打开其中的一把锁。
- 所以每人拥有他不在的两人组合对应的锁的钥匙,每人有C42=6把钥匙
-
记录如下:
|
A |
B |
C |
D |
E |
谁没有钥匙? |
| 1 |
|
|
√ |
√ |
√ |
AB |
| 2 |
|
√ |
|
√ |
√ |
AC |
| 3 |
|
√ |
√ |
|
√ |
AD |
| 4 |
|
√ |
√ |
√ |
|
AE |
| 5 |
√ |
|
|
√ |
√ |
BC |
| 6 |
√ |
|
√ |
|
√ |
BD |
| 7 |
√ |
|
√ |
√ |
|
BE |
| 8 |
√ |
√ |
|
|
√ |
CD |
| 9 |
√ |
√ |
|
√ |
|
CE |
| 10 |
√ |
√ |
√ |
|
|
DE |
∴ 至少要有10把锁,每人有6把钥匙。
然后我们来考虑一般情况,即有2n+1名科学家的情况。
一般情况
设相关人共有2n+1人,其中n人组成的“少数”团体不能打开安全门,任意n+1人组成的“多数”团体可以打开安全门。
"少数与多数"
- 两个不同的“少数”团体联合可成为多数团体
- 任一“少数”团体和不属该团体的任一人联合可成为多数团体
"需要几把锁?需要多少钥匙?"
每把锁与一个“少数”团体对应,至少要有C2n+1n把锁。
每人拥有他不在的“少数”团体对应的锁的钥匙,每人有C2nn把钥匙。
秘密共享-密码学
在密码学里,有专业术语来表示这种情况,叫做门限机制(t,n): 在n人之间共享秘密,其中任意 t 人可以重构出秘密,而任意 t−1 人都不能重构出秘密。
Shamir 门限机制 (t,n)
"基本思想"
通过秘密多项式,将秘密s分解为n个秘密,分发给持有者,其中任意不少于t个秘密均能恢复密文,而任意少于t个秘密均无法得到密文的任何信息。
"分发方法"
假设有秘密 K 要保护,任意取t−1个随机整数{x1,⋯,xt−1},构造如下多项式:
f(c)=K+x1c+x2c2+⋯+xt−1ct−1
其中,K∈Z,就是我们的秘密。
取n个不同的整数{c1,⋯,cn},取公开大素数p>n+1,K。计算bj≡f(cj)(modp),将(cj,bj)发送给第j个持有者。
"证明可行性"
就是判断任意t个方程是否有唯一解,任意t−1个方程是否有无穷多解。
"任意t个方程是否有唯一解"
取t个方程,则有解对应的行列式:
11⋮1c1c2⋮ctc12c22⋮ct2⋯⋯⋱⋯c1t−1c2t−1⋮ctt−1
由于ci互不相同,所以行列式不为零,有唯一解。
"任意t−1个方程是否有无穷多解"
对于任意t−1个方程,由于我们有t个未知数,所以有无穷多解。
"恢复秘密"
任意t个持有者联合,可以构造t个方程,从而可以恢复出秘密。
"例子:Secret:123; Shamir(3,5)"
"分配步骤"
-
首先确定 t 和 n,这里 t=3,n=5。
-
确定秘密 K=123,取模数 p=127,
-
秘密选择 t−1=2 个随机数 x1=2,x2=3,构造多项式:
f(c)=123+2c+3c2
-
选择 n=5 个不同的整数 c1=1,c2=2,c3=3,c4=4,c5=5,计算 bj≡f(cj)(modp),然后将 (cj,bj) 发送给第 j 个持有者:
| cj |
f(cj) |
bj |
| 1 |
128 |
1 |
| 2 |
139 |
12 |
| 3 |
156 |
29 |
| 4 |
179 |
52 |
| 5 |
208 |
81 |
"恢复秘密"
-
集齐任意t个钥匙,例如第一个人的(c1,b1),第二个人的(c2,b2),第五个人的(c5,b5),则可以构造如下方程组:
⎩⎨⎧K+1⋅x1+12⋅x2≡1(mod127)K+2⋅x1+22⋅x2≡12(mod127)K+5⋅x1+52⋅x2≡81(mod127)
解得
⎩⎨⎧K(mod127)=−4x1(mod127)=2x2(mod127)=3
所以密码K=123。
秘密共享-数论
"线性同余方程"
线性同余方程是指形如 ax≡b(modm) 的方程,其中 a,b,m 为整数,m>0。
- 当且仅当 gcd(a,m)∣b 时,线性同余方程有解。
- 当 gcd(a,m)=1 时,方程的解为 a−1b,且小于 m的非负整数解唯一。
- gcd(a,m)=1的情况,例如6⋅x≡3(mod8),解为 x=3 和 x=7。
- a−1 是 a 在模 m 意义下的逆元。
"什么是逆?"
设 a,b 为整数,m 为正整数,若 ab≡1(modm),则称 a 模 m 可逆,且 b 是 a 在模 m 意义下的逆元,记为 a−1。
"如何求逆?"
"大衍求一术"
求27−1(mod64)
102764
其中,64=2⋅27+10,所以
122710
其中,27=2⋅10+7,所以
52710
其中,10=1⋅7+3,所以
5773
其中,7=2⋅3+1,所以
19713
所以 27−1≡19(mod64)。
"扩展欧几里得算法"
用欧拉公式列出一系列等式,直到出现末尾的1。然后从最后一个等式开始,依次代入前面的等式,直到把gcd(a,b)写成sa+tm。其中,a的系数就是a−1。
例如,求27−1(mod64):
6427107=2⋅27+10=2⋅10+7=1⋅7+3=2⋅3+1
所以
1=7−2⋅3=7−2⋅(10−1⋅7)=3⋅7−2⋅10=3⋅(27−2⋅10)−2⋅10=3⋅27−8⋅10=3⋅27−8⋅(64−2⋅27)=19⋅27−8⋅64
所以 27−1≡19(mod64)。
"中国剩余定理"
设 m1,m2,⋯,mk 为两两互质的正整数,a1,a2,⋯,ak 为任意整数,记M=m1m2⋯mk,则同余方程组
⎩⎨⎧x≡a1(modm1)x≡a2(modm2)⋮x≡ak(modmk)
有小于 M 的唯一正整数解x=M1M1−1a1+M2M2−1a2+⋯+MkMk−1ak(modM),其中Mi=M/mi,Mi−1是Mi在模mi意义下的逆元。
"如何求解?"
- 计算 M=m1m2⋯mk。
- 计算 Mi=M/mi。
- 计算 Mi−1。
- 解为 x=M1M1−1a1+M2M2−1a2+⋯+MkMk−1ak(modM)。
例如,求解 x≡2(mod3),x≡3(mod5),x≡2(mod7):
MM135M1−1M1−1x=3⋅5⋅7=105=5⋅7=35,M2=3⋅7=21,M3=3⋅5=15≡1(mod3),21M2−1≡1(mod5),15M3−1≡1(mod7)=2,M2−1=1,M3−1=1=35⋅2⋅2+21⋅1⋅3+15⋅1⋅2=233≡23(mod105)
Asmuth-Bloom 门限机制
"参数选取"
记秘密为K,n个人,t个人可以恢复秘密。
选取两两互素的整数p和m1,m2,⋯,mn,满足p>K以及m1<m2<⋯<mn,且
mn−t+2⋯mnm1⋯mt>p
也就是说任意t个整数的乘积都大于p乘以任意t−1个整数的乘积。
"秘密分割"
为了选出一个能代表K的数K′<m1⋯mt,我们选取一个随机数r∈N,满足0≤r≤pm1⋯mt−1。记K′=K+rp。
K′=K+rp≤K+(pm1⋯mt−1)p=K+m1⋯mt−p≤m1⋯mt。
令kj≡K′(modmj),1≤j≤n,将秘密份额(kj,mj)分发给第j个持有者。
"秘密恢复"
当t个持有者联合时,由(kj,mj),可构建方程组
kj≡K′(modmj)也就意味着K′≡kj(modmj)
⎩⎨⎧x≡k1(modm1)x≡k2(modm2)⋮x≡kt(modmt)
然后可由中国剩余定理求解x,
"证明可行性"
判断任意t个方程可行,任意t−1个方程不可行。
"为什么任意t个方程可行?"
由于中国剩余定理,所以任意t个方程都有小于mk1mk2⋯mkt的唯一解x。
当我们限制了K′<m1⋯mt
那么n个方程解出来有唯一解K′<m1⋯mt≤mk1mk2⋯mkt
而对任意t个方程能解出唯一解x≤mk1mk2⋯mkt,由于区间的限制以及解的唯一性,所以x=K′。
如果x=K′,则t个方程的解不唯一,与中国剩余定理矛盾。

"为什么任意t−1个方程不可行?"
因为对任意t−1个方程,我们解出的那个唯一解x<mk1mk2⋯mkt−1的。
而mk1mk2⋯mkt−1<q∗mk1mk2⋯mkt。
所以在mk1mk2⋯mkt−1和q∗mk1mk2⋯mkt之间,仍有数解,所以不可行。
"问题背景:"
如何给出一种合理、客观、定量、可操作的网页排序规则,使“重要”的网页排在前面?
随机矩阵
我们先对矩阵的一些概念进行定义:
- 各行(列)元素之和均为1的非负方阵称为行(列)随机矩阵
- 各行和各列元素之和均为1的非负方阵称为双随机矩阵
任一随机矩阵的模最大特征值为 1
"证明"
-
证明 1 是随机矩阵的特征值。
- 对行随机矩阵,我们很容易就能取到特征向量为全为1的列向量,此时特征值为1。
- 对列随机矩阵,因为转置前后特征值相同,所以也是1。
-
证明 1 是随机矩阵的模最大特征值。
- 设 λ 是行随机矩阵P=Pij的特征值,非零向量 x=(x1,x2,⋯,xn)T 为属于特征值λ的特征向量。设∣xi∣=max{∣x1∣,∣x2∣,⋯,∣xn∣}
- 由 Px=λx,可得 λxi=∑j=1npijxj。
- 对上式两边取模,∣λ∣∣xi∣=∣∑j=1npijxj∣≤∑j=1n∣pij∣∣xj∣≤∑j=1n∣pij∣∣xi∣=∣xi∣∑j=1n∣pij∣=∣xi∣,即 ∣λ∣≤1。
所以,1是随机矩阵的特征值,且模最大。
网页重要度
为了排序网页,我们首先肯定需要定量地描述网页的重要度。于是,我们给出以下网页重要度的原则与假设:
"某网页重要,是因为有其他重要的网页链接到它"
- 传递性:重要度大的网页链接到网页A时,它对A重要度的贡献大于重要度小的网页
- 某网页对其他网页重要度的贡献之和等于它自身的重要度
- 等效性:网页对它所链接的每个网页的重要度贡献相等
- 某网页对其他网页的重要度贡献与它所链接的网页数量成反比
- 叠加性:链接到网页A的网页越多,A越重要
- 网页A的重要度是所有链接到它的网页的重要度贡献之和
- 无关性:网页链接其它网页的多少,与其本身的重要度无关
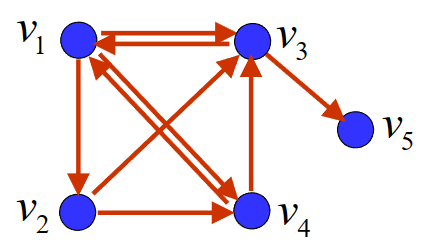
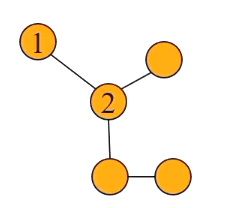
网络链接图
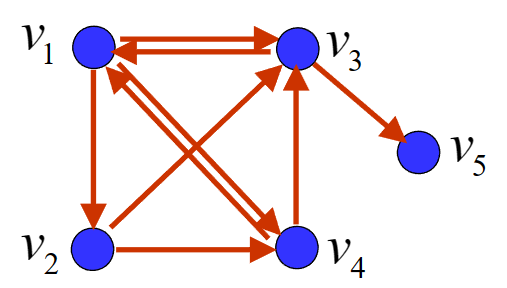
我们用有向图来表示互联网中网页之间的连接关系,并称之为网络链接图,我们定义顶点为网页V={v1,v2,⋯,vn},弧为网页之间的有向链接。
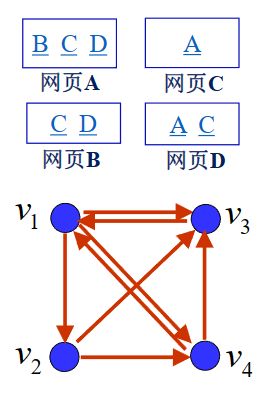
"例子"
如图所示,我们记网页A、B、C、D为v1,v2,v3,v4,则有v1指向v2,v3,v4; v2指向v3,v4; v3指向v1; v4指向v1,v3。
网页重要度的矩阵表示
记网页vi的重要度为xi,出度为qi,根据网页重要度中的假设,我们有
-
网页vi对其他网页重要度贡献之和等于它自身的重要度xi
-
网页vi对它链接的qi个网页的重要度贡献相等,为qixi
-
若链接到vi的网页有vj1,vj2,⋯,vjqi,则有
xi=qj1xj1+qj2xj2+⋯+qjqixjqi
记pij为网页vi到vj的链接概率,即vi链接到vj的概率,我们有
pij={qi1,0,若vi链接到vj若vi不链接到vj
所以,我们可以将上式改写为
xi=j=1∑npijxj
记矩阵P=(pij)n×n为初始链接矩阵,x=(x1,x2,⋯,xn)T为网页重要度向量,我们有
x=Px
显然,x是P的特征向量,对应的特征值为1。且Rank(I−P)<n(其实I−P的每一列和为0,将最后一行前的所有行相加至最后一行,得到0,所以Rank(I−P)<n)。
因为初始链接矩阵P的每一列和为1,所以P是列随机矩阵。
"例子"
如图所示,我们记网页A、B、C、D为v1,v2,v3,v4,则有v1指向v2,v3,v4; v2指向v3,v4; v3指向v1; v4指向v1,v3。
我们有(pij是从vj到vi的概率)
P=03131310021211000210210
所以:
I−P=1−31−31−3101−21−21−1010−210−211
可以解得:
x=3112314319316
但是,线性方程组x=Px还会有特殊情况:
"这个线性方程组有多个解"
若P有两个属于特征值1的线性无关的特征向量,我们就无法得到唯一的网页重要度向量x。如下图。
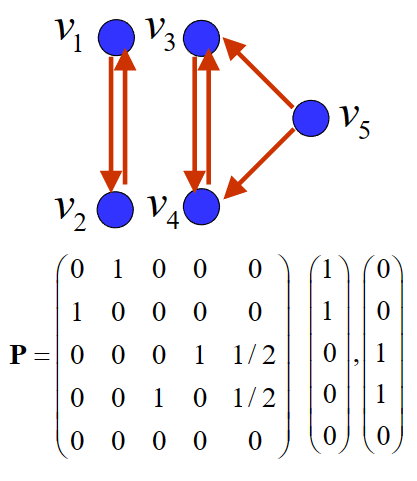
悬挂网页
若某网页不链接到任意其它网页,我们称之为悬挂网页。显然,悬挂网页的出度为0,但它的重要度不为0,因为有其他网页链接到它。所以我们需要对初始链接矩阵P进行修正。
将链接矩阵P的该列所有元素由0修改为n1,得到(修正)链接矩阵P。
我们记悬挂网页为第i个网页,记dT=(0,0,⋯,0,1,0,⋯,0),其中索引至悬挂网页的值为1,其余为0。则有
P=P+n11dT
"悬挂网页例子"
"图"
如下图中,修正的链接矩阵为多少?
"修正连接矩阵"
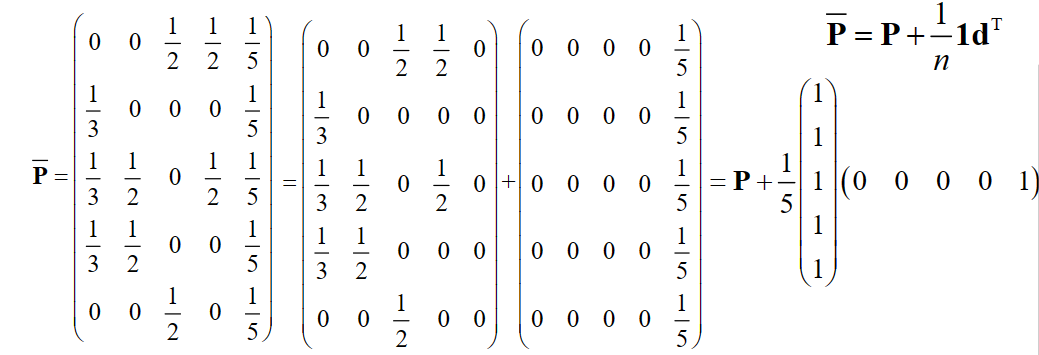
多解修正
若P有两个属于特征值1的线性无关的特征向量,我们就无法得到唯一的网页重要度向量x。
于是,我们对P进行修正,使得P成为完全正矩阵,即P的所有方阵子式的行列式都大于0。
我们先给出修正的方法:
P=αP+(1−α)n111T
其中,α为修正系数,α=0.85。P是完全正矩阵与列随机矩阵的结合。
"证明P是列随机矩阵"
1TP=α1TP+(1−α)1Tn111T=α1T+(1−α)1T=1T
所以,P是列随机矩阵。
注意,我们说的是P是列随机矩阵,而我们要求的是Px=x,所以这里的1T并不是P的特征向量。
"证明P关于特征值1的特征向量有且只有一个"
- 存在性:P是列随机矩阵,所以1是P的特征值,且1是属于特征值1的特征向量。
- 唯一性:用反证法:
设v=(v1,v2,⋯,vn)T,w=(w1,w2,⋯,wn)T是完全正、列随机矩阵P的属于特征值1的特征向量,且v=w。令xi=−VWvi+wi,i=1,2,⋯,n,其中W=∑i=1nwi,V=∑i=1nvi=0,因为v和w线性无关,且
j=i∑npijxj=j=i∑npij(−VWvj+wj)=−VWj=i∑npijvj+j=i∑npijwj=−VWvi+wi=xi
j=i∑npijvj=vi,是因为v=(v1,v2,⋯,vn)T是属于特征值1的特征向量,经计算可得。
所以有i=1∑nxi=i=1∑n(−VWvi+wi)=−VWi=1∑nvi+i=1∑nwi=−VWV+W=0,即x是P的属于特征值1的特征向量,所以x的分量之和为0。
我们接下来尝试证明:如果x是P的属于特征值1的特征向量,那么x的分量之和不为零,从而与上面的结论矛盾。这也就证明了属于特征值1的特征向量有且只有一个。
证明:
设x是P的属于特征值1的特征向量,则xi=j=1∑npijxj
如果i=1∑nxi=0,则x的分量有正有负,所以
∣xi∣=∣j=1∑npijxj∣<j=1∑npij∣xi∣
所以
i=1∑n∣xi∣<i=1∑nj=1∑npij∣xj∣=j=1∑ni=1∑npij∣xj∣=j=1∑n(∣xj∣i=1∑npij)=j=1∑n∣xj∣
矛盾,所以x的分量之和不为零。
所以,P关于特征值1的特征向量有且只有一个。
Perron-Frobenius定理
把上述结论一般化,我们有:
"Perron定理"
若矩阵 A是完全正矩阵,则
- A的模最大特征值唯一,且为正实数
- 该特征值代数重数为1
- 存在该特征值的一个特征向量,其分量全为正
"Perron—Frobenius定理"
若矩阵 A是非负不可约(irreducible)矩阵,则
- A的模最大特征值为正实数
- 该特征值代数重数为1
- 存在该特征值的一个特征向量,其分量全为正
"不可约矩阵"
不可约矩阵当且仅当矩阵对应的有向图是强连通图。
强连通图是指在有向图G中,如果对于每一对vi,vj,vi=vj,从vi到vj和从vj到vi都存在路径,则称G是强连通图。
"不可约矩阵的代数描述"
若干个初等对换矩阵的乘积称为置换矩阵(permutation matrix)
- 置换矩阵每行和每列都恰有一个元素为 1,其余元素都为 0
- 若存在置换矩阵 Q,使得 QTAQ=(XY0Z),其中 X 和 Z 均为方阵,则称 A 为可约矩阵(reducible matrix),否则 A 为不可约矩阵
整个互联网有相当多且稀疏的网页,所以我们需要一个好的算法来求解网页重要度向量x。
幂法
幂法是计算矩阵模最大特征值和对应的特征向量的一种迭代算法
任取初始向量x(0)>0,且i=1∑nxi(0)=1,我们通过迭代计算x(k)=Px(k−1),直到x(k)收敛
1Tx(k)=1TPx(k−1)=1Tx(k−1)=1
我们展开x(k)=Px(k−1)
P=P+n11dT
P=αP+(1−α)n111T
x(k)=Px(k−1)=αPx(k−1)+(1−α)n111Tx(k−1)=αPx(k−1)+(1−α)n11=α(P+n11dT)x(k−1)+(1−α)n11=αPx(k−1)+αn11dTx(k−1)+(1−α)n11
完全正、列随机矩阵幂法的收敛性
1TP=1T
P=(pij)n×n
记V为满足1Tv=1的n维列向量v={v1,v2,⋯,vn}全体组成的集合。记∥v∥1=i=1∑n∣vi∣。
对任意的v∈V,我们取w=Pv,因为
1Tw=1TPv=1Tv=0
所以w∈V。
我们接下来尝试证明∥w∥1=∥Pv∥1≤c∥v∥1,其中c<1。
- w=0,显然成立。
- w=0,记w=(w1,w2,⋯,wn)T,ei=sgn(wi),则有
∥w∥1=i=1∑n∣wi∣=i=1∑neiwi=i=1∑n(eij=1∑npijvj)=i=1∑n(j=1∑neipijvj)=j=1∑n(i=1∑neipijvj)=j=1∑n(vji=1∑neipij)≤j=1∑n(∣vj∣∣i=1∑neipij∣)
记c=1≤j≤nmax∣i=1∑neipij∣<1,则有
∥w∥1≤j=1∑n(∣vj∣∣i=1∑neipij∣)≤j=1∑n(∣vj∣c)=cj=1∑n∣vj∣=c∥v∥1
所以,∥w∥1≤c∥v∥1,其中c<1。
记v0=x(0)−X∈V,我们有
1Tv0=1Tx(0)−1TX=1−1=0
所以v0∈V。
由于PX=X,
x(k)=Pkx(0)=Pk(X+v0)=X+Pkv0
由于∥Pkv0∥1≤ck∥v0∥1,所以
∥x(k)−X∥1≤ck∥v0∥1
所以,x(k)收敛到X,得证。
随机浏览
按以下模式浏览互联网的网页
- 有时从当前网页的链接中随机打开一个网页
- 有时键入网址新建一个网页
- 从任一网页开始,充分长时间后,访问各网页的概率即为网页重要度
经过统计,随机打开网页的次数与键入网址新建网页的次数之比约为5:1,这就是α=0.85的来源。
随机概率
记事件 {Xm=j} 为时刻 m 访问网页 vj,则P{Xm=i∣Xm−1=j}=pij
若 P{Xm=j}=xj,则P{Xm=i}=j=1∑nP{Xm=i∣Xm−1=j}P{Xm−1=j}=j=1∑npijxj
记 x(m)=(P{Xm=1},P{Xm=2},⋯,P{Xm=n})T,则有x(m)=Px(m−1)
随机过程
随机过程是描述随机现象随时间推移而演化的一类数学模型。
在一族随机变量{X(t),t∈T}中T为参数集,t是参数。{X(t),t∈T}称为参数为t的随机变量。
Markov过程
在已知目前的状态(现在)的条件下,它未来的演变(将来)不依赖于它以往的演变(过去)。
在随机序列{X(n),n=0,1,2,⋯}中(Xn有限或可列),我们对于任意的n≥0,有
P{Xn+1=j∣Xn=i,Xn−1=in−1,⋯,X0=i0}=P{Xn+1=j∣Xn=i}
03 Nim游戏
"问题背景"
现有n堆硬币,每堆数量一定。两人轮流取硬币,每次只能从其中一堆中取,且每次取至少一枚。取到最后一枚硬币的一方获胜。
那么,这个游戏是否有必胜策略?若有,应如何取胜?
特殊情况
我们先从考虑一下这个游戏的特殊情况。
"两堆硬币"
"1 1"
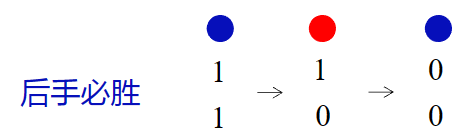
"k 1"
先手第一步将硬币数转换为 1 1
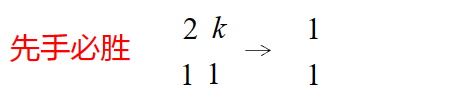
"k k"
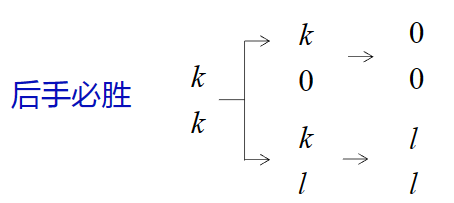
"k l"
先手第一步将硬币数转换为 l l 形式
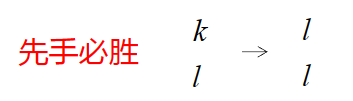
"三堆硬币"
"1 1 1"
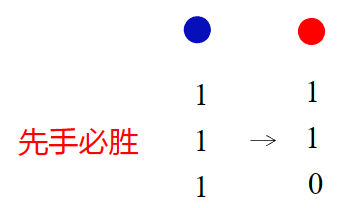
"l k k"

"复杂情况"
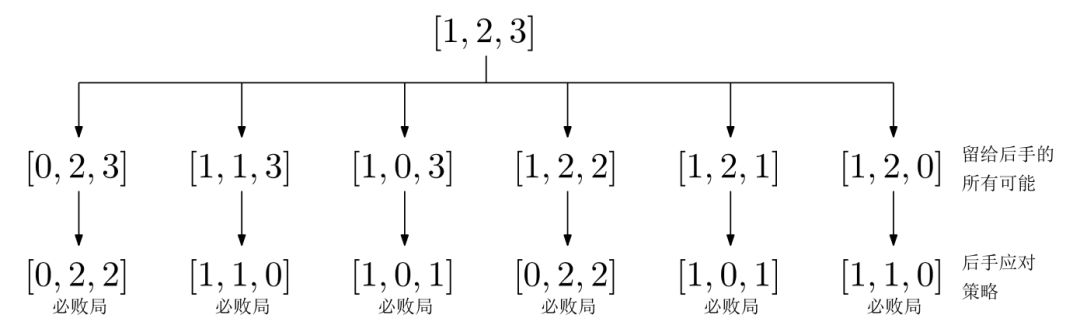

但是,这些复杂情况我们就不能一一列举了。我们需要找到一种方法,能够将任意情况转换为上述的特殊情况。
安全状态
我们先来定义一下什么是安全状态。
若无论对方如何取均不会获胜,或者无论对方如何取,己方下一次取后均可变为一个安全状态的,称为安全状态。
若对方至少存在一种获胜的取法,己方下一次取无法变为一个安全状态的,称为不安全状态。
必胜策略:己方取法使得下一状态为安全状态。
Nim游戏的必胜策略
二进制与位和
将每堆硬币数表示为二进制。将所有二进制数的每一位数字分别求和,其尾数称为位和。(其实就是异或)
- 只有一堆硬币时,位和不可能全为0
- 每次从某一堆中取若干枚硬币,该堆硬币的二进制数发生变化,且至少有一位位和发生变化
位和与安全状态
若所有位和均为 0 ,则当前状态为安全的,否则为不安全
- 若当前状态安全,对任意取法,状态变为不安全
- 若当前状态不安全,存在一种取法,状态变为安全
- 按自左至右的顺序确定第一个数字之和不为 0 的位,寻找该位数字为 1 的堆,从该堆中取走若干枚使得状态变为安全

04 组合群式 - 伪币辨识
"问题背景"
12枚外观相同的硬币中有一枚是伪币,伪币质量与真币不同。天平一次称量只能比较两端质量大小,不能读出质量数值。能否用天平称量三次找出伪币,并说明伪币相对真币偏轻或偏重。
组合群式
群式分为组合群试和概率群式。
- 组合群式:假定n枚硬币中有k枚是伪币,如何用尽可能少的检测次数(在任何情况下)找出全部的伪币
- 概率群试:假定n枚硬币相互独立地以概率p可能是伪币,如何找出全部的伪币,使平均检测次数尽可能少
这个问题是组合群试的问题。概率群式我们将在疾病检测中讨论。
特殊情况
后一次称量依赖于之前称量结果的方案为自适应(adaptive)的,否则称为非自适应(non-adaptive)的
自适应方案
硬币真伪的可能性共有12×2=24种。每一种称量结果对应一种可能性,不同称量结果对应的可能性各不相同
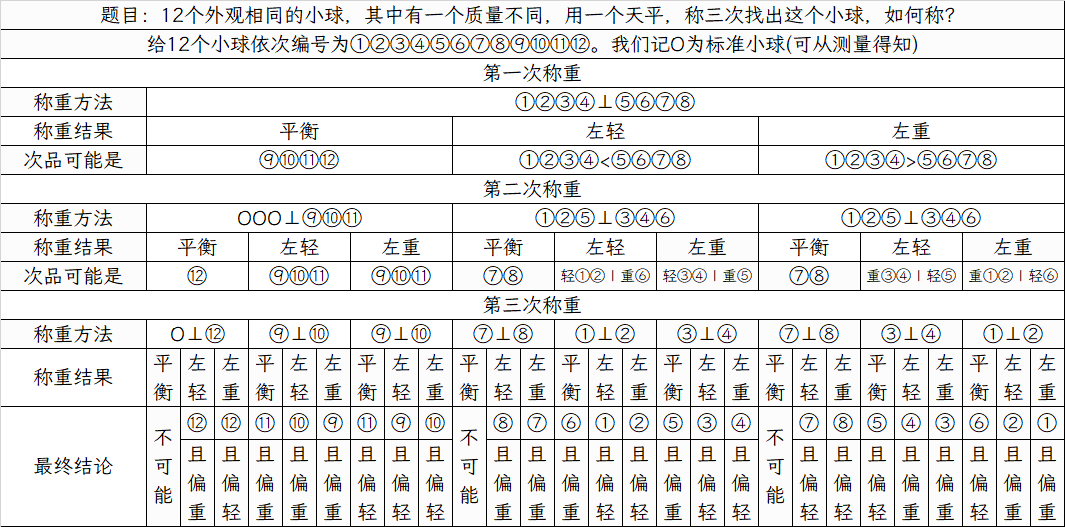
非自适应方案
自适应方案缺点在于三次实验不能同时进行,这对一些称量周期大的实验来说是不可接受的。因此我们考虑非自适应方案。
我们先给出十二枚硬币三种称量
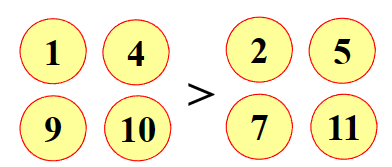
如果伪币为重,则在1、4、9、10中,如果伪币为轻,则在2、5、7、12中
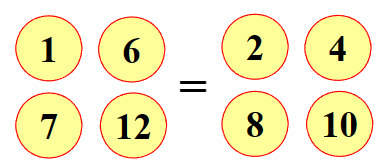
此时不知伪币轻重,但是可以确定伪币在补集3、5、9、11中
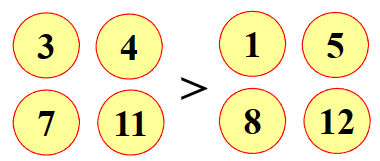
如果伪币为重,则在3、4、7、11中,如果伪币为轻,则在1、5、8、12中
把我们判断轻重的部分放在一起,可以得到如下的判断表
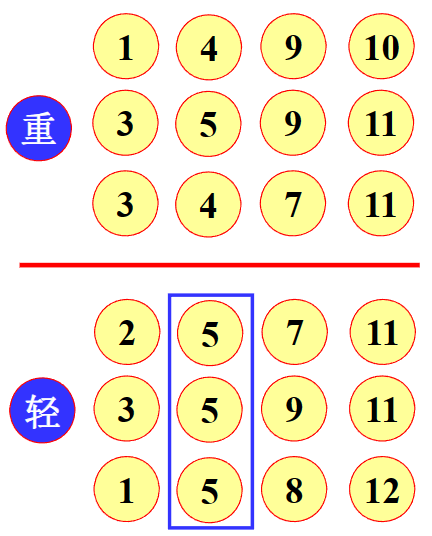
每个判断中取三组的交集,即可得到伪币的位置
一般结论
对任意整数w>2
- 若 3≤n≤23w−3,则存在一种非自适应的称量方案,使用 w 次称量可从 n 枚硬币中辨别伪币并确定轻重。
- 若 n>23w−3,则不存在自适应的称量方案,用 w 次称量即可从 n 枚硬币中辨别伪币并确定轻重。
一般情况的非自适应方案
构造要能实现非自适应方案,需要满足Dyson集,即满足以下条件的w元向量子集S⊆{−1,0,1}w
- ∑v∈Sv=0,确保天平两端硬币数相等
- 若v∈S,则−v∈/S,确保伪币唯一且确定轻重
我们要先构造出这样的向量集,然后再放上去称。例如,对于w=3,我们可以构造出如下的集合
S={(1,1,−1)(−1,0,−1)(1,0,0),,,(−1,−1,0)(0,1,0)(1,−1,0),,,(0,0,1)(−1,1,1)(−1,0,1),,,(1,−1,1)(0,−1,−1)(0,1,−1),,}
对应到那12个硬币,1表示在天平左侧,−1表示在天平右侧,0表示不在天平上。我们可以验证,这个集合满足Dyson集的条件。
如果最后的结果如下图所示,
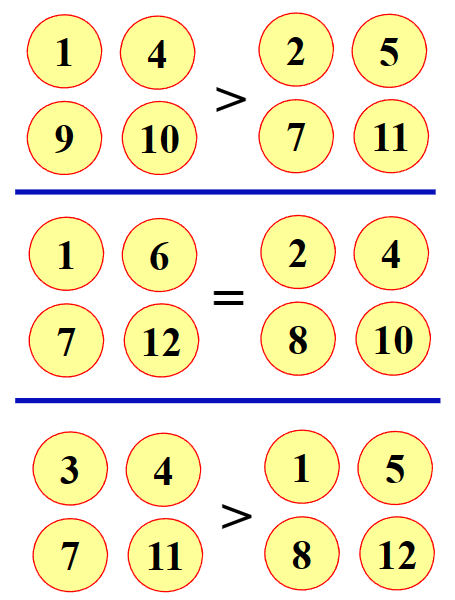
那么我们可以得到1,0,1(1表示为重)这样的向量,这个向量就与伪币有关。如果我们硬币的标记为1,0,1,那它就是重伪币;如果为-1,0,-1,那它就是轻伪币。
构造Dyson集
构造映射f:{−1,0,1}→{−1,0,1},使得f(−1)=0,f(0)=1,f(1)=−1。例如(−1,0,1,1)→(0,1,−1,−1)。
记集合S(x)={x,f(x),f(f(x)),−x,−f(x),−f(f(x))},S(x)+={x,f(x),f(f(x))}。我们要选取的就是属于S(x)+的向量。
因为我们不要{1,1,⋯,1},{0,0,⋯,0},{−1,−1,⋯,−1},且不要S(x)−={−x,−f(x),−f(f(x))}中的向量,所以我们可选取的向量个数为23w−3个,也就印证了一般结论中的第一个结论。
那么如何选取v∈S(x)使得∑v∈Sv=0呢?我们先寻找{−1,0,1}w中63w−3个基本向量,每个对应着不同的S(x)+。
然后需要分情况讨论。
w 次称量可从 n 枚硬币中辨别伪币并确定轻重
- n=3k时,因为x+f(x)+f(f(x))=0,所以我们选取:S+(v1)∪S+(v2)∪S+(v3)∪⋯∪S+(vk)
- n=3k+1时
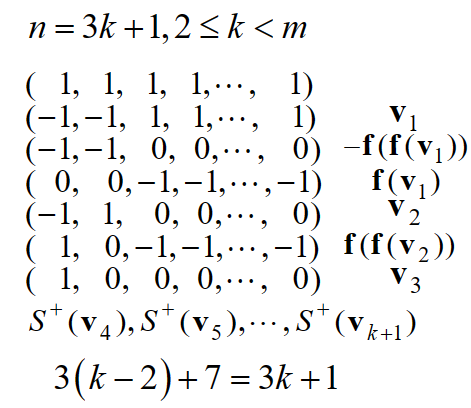
- n=3k+2时
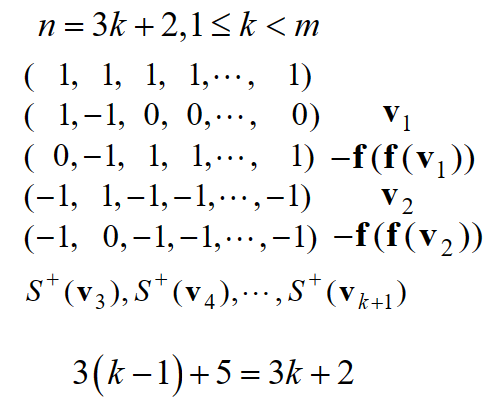
至此,我们给出了一般情况下的非自适应方案。这就是为什么我们在第一次称量中要把硬币分成三组的原因。
05 概率群式 - 疾病检测
"问题背景"
假定 n 个人相互独立地以概率 p 患病,如何找出全部的病人,使平均检测次数尽可能少?
名词介绍
记 A 为患病,B 为检测结果为阳性,疾病检测方法的性能指标为
- 灵敏度(sensitivity)p=P(B∣A) :患病者被检测为阳性(positive)的概率
- 特异度(specificity)q=P(B∣A) :未患病者被检测为阴性(negative)的概率
设疾病的发病率为 r ,则被检测出阳性的情况下患病的概率为
P(A∣B)=P(B∣A)P(A)+P(B∣A)P(A)P(B∣A)P(A)=pr+(1−q)(1−r)pr
概率群式
概率群式:假定 n 个人相互独立地以概率 p 患病,如何找出全部的病人,使平均检测次数尽可能少?
如何选择群式方案?我们要考虑平均检测次数、检测阶段数、每人最大检测次数、每组最多样本数、方案的可操作性、检测的灵敏度与特异度等多个因素
两阶段群式
将 n 人的样本混合后检测。若结果为阴性,说明这 n 人均未感染。若结果为阳性,说明这 n 人中至少有一人已感染。此时逐个检测每个人样本。
检测次数
- 混合样本阴性概率为 (1−p)n ,总检测次数为 1 ;
- 混合样本阳性概率为 1−(1−p)n ,总检测次数为 n+1 。
- 检测次数的数学期望为 1⋅(1−p)n+(n+1)⋅(1−(1−p)n) ;
- 平均检测次数的数学期望为 n1⋅(1−p)n+(n+1)⋅(1−(1−p)n) 。
矩阵检测方案
自适应思路
将 m×n(m≤n)个人按矩阵排好,先检测每行样本,若结果为阴性,说明这 m 人均未感染。若结果为阳性,说明这 m 人中至少有一人已感染。此时逐个检测每列样本。
检测次数
这里的每行就相当于两阶段群式中的混合样本,每列就相当于两阶段群式中的每个人样本。
非自适应思路
将 m×n(m≤n)个人按矩阵排好,对每行每列分别进行检测。通过检测结果确定感染者的位置。
检测次数
总检测次数均为 m+n 。
三阶段检测方案
第一阶段:有 n 个人,进行总体的混合检测,若结果为阴性,说明这 n 人均未感染。若结果为阳性,说明这 n 人中至少有一人已感染。进入第二阶段。
第二阶段:将这 n 人分成 A ,B 两组,每组 n/2 人,先对 A 组进行检测,若结果为阴性,说明这 n/2 人均未感染,且确定感染者在 B 组。若结果为阳性,说明这 n/2 人中至少有一人已感染,但仍需确定 B 组是否有感染者,此时对 B 组进行总体的混合检测。
第三阶段:对有感染者的组进行逐个检测,确定感染者的位置。
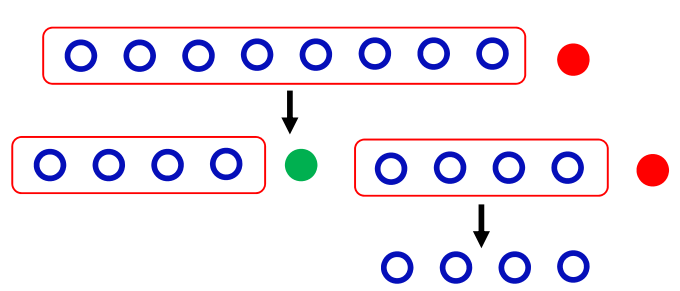
计算概率:
第一阶段
- 结果为阴性的概率为 (1−p)n ,总检测次数为 1 ;
第二阶段
-
A 组结果为阴性的概率为 (1−p)n/2 ;则B组肯定为阳性,这发生的概率为 1−(1−p)n/2
==第一阶段总体检测+检测A组+逐个检测B组1+1+n/22+n/2
-
A 组结果为阳性的概率为 1−(1−p)n/2 ,B 组结果为阴性的概率为 (1−p)n/2 ,总检测次数为
==第一阶段总体检测+总体检测A组+逐个检测A组+总体检测B组1+1+n/2+13+n/2
-
A 组结果为阳性的概率为 1−(1−p)n/2 ,B 组结果为阳性的概率为 1−(1−p)n/2 ,总检测次数为
==第一阶段总体检测+总体检测A组+逐个检测A组+总体检测B组+逐个检测B组1+1+n/2+1+n/23+n
所以总检测次数的数学期望为
=(1−p)n⋅1+(1−p)2n(1−(1−p)2n)⋅(2+2n)+(1−(1−p)2n)(1−p)2n⋅(3+2n)+(1−(1−p)2n)2⋅(3+n)n+3−(n+1)(1−p)2n−(1−p)n
平均检测次数的数学期望为
1+3n−(1+n1)(1−p)2n−n1(1−p)n
06 Monty Hall问题
"问题背景"
舞台上有三扇道具门,其中一扇门后置有一辆汽车,另两扇门后各置有一头山羊。竞猜者可任选其中一扇门并获赠门后物品。当竞猜者选择了其中一扇门后,主持人打开了另两扇门中的一扇,门后面是一头山羊。
- 主持人知道汽车所在位置。他打开的门既不是竞猜者选择的,也不是后置汽车的。若有两扇门符合以上要求,他以相同概率选择其中一扇
- 主持人允许竞猜者改变之前的选择,竞猜者为增加获得汽车的可能性,是否应该改变当前的选择?
初次见到这个问题的人,大多数都会认为改变选择不会增加获得汽车的可能性。但是事实上,改变选择会使获得汽车的概率提高一倍。
枚举法
我们不妨用枚举法来验证一下。
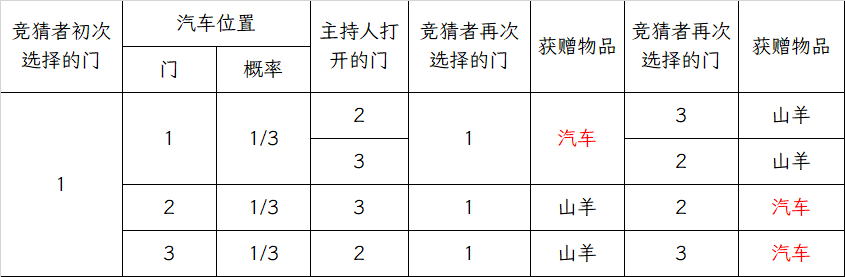
可见,若改变选择,获得汽车的概率为 32 ;若不改变选择,获得汽车的概率为 31 。
概率论方法
我们再用概率论的知识来计算一下这个问题。
假设竞猜者初次选择1号门,记 Ci 为汽车在 i 号门后的事件,M 为主持人打开 2 号门的事件,则有
P(M∣C1)=21;P(M∣C2)=0;P(M∣C3)=1
若竞猜者改变选择,则获得汽车的概率为
P(C3∣M)===P(M∣C1)P(C1)+P(M∣C2)P(C2)+P(M∣C3)P(C3)P(M∣C3)P(C3)21⋅31+0⋅31+1⋅311⋅3132
若竞猜者不改变选择,则获得汽车的概率为
P(C1∣M)===P(M∣C1)P(C1)+P(M∣C2)P(C2)+P(M∣C3)P(C3)P(M∣C1)P(C1)21⋅31+0⋅31+1⋅3121⋅3131
可见,若改变选择,获得汽车的概率为 32 ;若不改变选择,获得汽车的概率为 31 。
变种
被蒙在鼓里的主持人
如果主持人不知道汽车在哪扇门后,那么他打开的门后面有可能是汽车,也有可能是山羊。此时,改变选择和不改变选择的获得汽车的概率均为 21 。
因为此时,如果我们再
假设竞猜者初次选择1号门,记 Ci 为汽车在 i 号门后的事件,记M 为主持人打开 2 号门后是山羊的事件,则有
P(M∣C1)=21;P(M∣C2)=0;P(M∣C3)=21
通过计算可得,若改变选择,获得汽车的概率为 21 ;若不改变选择,获得汽车的概率为 21 。
由此我们可以看出,在之前的问题中,主持人是有额外信息的,他知道汽车在哪扇门后,这导致了改变选择和不改变选择的获得汽车的概率不同。
n 扇门
有 n 扇道具门,其中一扇门后置有一辆汽车,其他 n−1 扇门后各置有一头山羊
- 当至少有三扇门还未打开时,竞猜者选择其中一扇未打开的门,主持人以相同概率打开竞猜者未选择且后面是山羊的门中的任意一扇,并允许竞猜者改变之前的选择。继续上述过程直至只有两扇门还未打开
- 在游戏进行过程中每次允许竞猜者改变选择时,竞猜者应采取怎样的策略
n 扇门,k 辆车
有 n 扇道具门,其中 k 扇门后置有一辆汽车,其他 n−k 扇门后各置有一头山羊
- 竞猜者选择其中一扇门后,主持人以相同概率打开了其他 n−1 扇门中的 m 扇,1≤m≤n−2 ,其中 j 扇门后各有一辆汽车, m−j 扇门后各有一头山羊
- 主持人允许竞猜者改变之前的选择,竞猜者是否应该改变当前的选择
n 扇门,多种奖品
有 n 扇道具门,其中 ni 扇门后各置有价值为 vi 的奖品,i=1,2,⋯,m
- 竞猜者选择其中一扇门后,主持人以相同概率打开了其他 n−1 扇门中的一扇,并允许竞猜者改变之前的选择。竞猜者看到打开的门后的奖品后,是否应该改变当前的选择
07 赠券收集问题
"问题背景"
一套赠券共有 N 种,商家在每件商品中随机放入一张赠券。假设每件商品中放入各种赠券的概率相同,那么集齐全套赠券平均需购买多少件商品?
方法一:德摩根定律
定义随机变量 X 为“集齐全套赠券需购买的商品件数”,E(X)=i=1∑Ni⋅P(X=i)。记 Bi为事件“购买 i 件商品后集齐全套赠券”,记 Aij为事件“购买 i 件商品后收集到第 j 种赠券”。则有
P(Aij)=P(Bi)====1−P(Aij)=1−(1−N1)iP(Ai1∩Ai2∩⋯∩AiN)1−P(Ai1∩Ai2∩⋯∩AiN)1−P(Ai1∪Ai2∪⋯∪AiN)1−(j=1∑NP(Aij)−1≤j1<j2≤N∑P(Aij∩Aik)+⋯+(−1)N−1P(Ai1∩Ai2∩⋯∩AiN))
分析括号中的第二项,对任意固定的j,k,1≤j<k≤N,Aij∩Aik表示购买 i 件商品后未收集到第 j 种和第 k 种赠券,有P(Aij∩Aik)=(1−N2)i。
同理,对任意1≤j1<j2<⋯<jk≤N,Aij1∩Aij2∩⋯∩Aijk表示购买 i 件商品后未收集到第 j1 种、第 j2 种、⋯、第 jk 种赠券,有P(Aij1∩Aij2∩⋯∩Aijk)=(1−Nk)i。因此,有
P(Bi)=====1−(j=1∑NP(Aij)−1≤j1<j2≤N∑P(Aij∩Aik)+⋯+(−1)N−1P(Ai1∩Ai2∩⋯∩AiN))1−j=1∑N(1−N1)i−1≤j1<j2≤N∑(1−N2)i+⋯+(−1)N−1(1−NN)i1−((N1)(1−N1)i−(N2)(1−N2)i+⋯+(−1)N−1(NN)(1−NN)i)1−j=1∑N(−1)j−1(Nj)(1−Nj)ij=0∑N(−1)j(Nj)(1−Nj)i
所以其期望为:
i=1∑Ni⋅P(X=i)=i=1∑Ni⋅j=0∑N(−1)j(Nj)(1−Nj)i
方法二:几何分布
记随机变量 X 为“集齐全套赠券购买的商品件数”,定义随机变量 Y 为“从收集到 k−1 种赠券到 k种赠券购买的商品件数”,则有:
X=Y1+Y2+⋯+YN
我们考察Yk。Yk=j 意味着先购买的 j−1 件商品中的赠券均为已收集到的 k−1 种中的一种,第 j 件商品中有未收集到的 N−k+1 种赠券中的一种。可知,Yk 服从参数为 NN−k+1 的几何分布
"分布回忆"
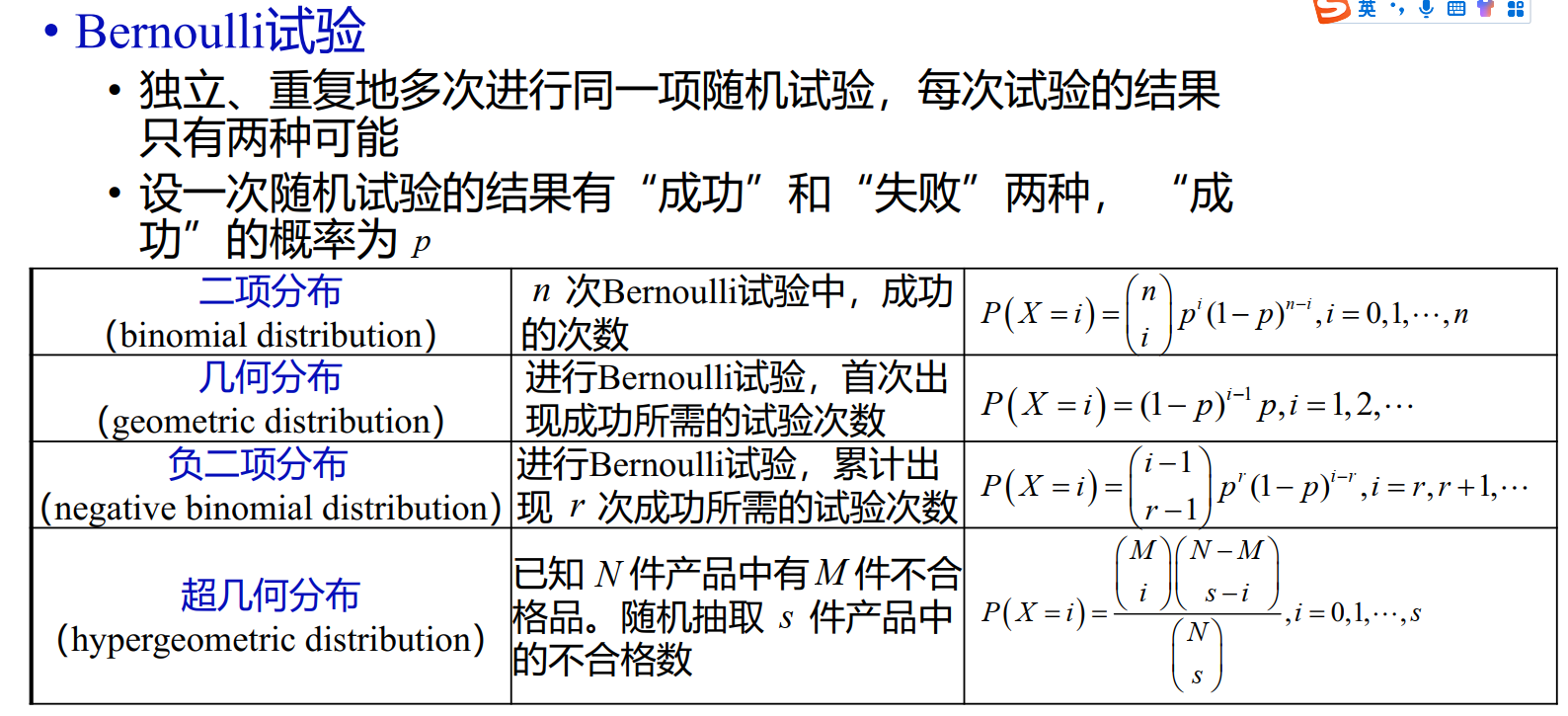
所以,根据几何分布的性质,有E(Yk)=N−k+1N。因此,E(X)=k=1∑NE(Yk)=k=1∑NN−k+1N=Nk=1∑Nk1。
显然,方法二的计算量要小于方法一。而且,方法二的思路更加简单,更加容易理解。
08 赌徒破产问题与Pascal问题
"问题背景"
-
赌徒破产问题:
一个赌徒在初始时拥有 h 个单位财富。在每局赌博中以概率 p 赢一个单位财富,以概率 q=1−p 输一个单位财富。各局赌博结果独立。当赌徒的财富达到 N 个单位或 0 个单位(破产)时停止赌博。求赌徒破产的概率。
-
Pascal问题:
A,B两人玩一种游戏,初始时两人各有12分。一次掷三枚骰子,若点数恰为11则A胜B负,点数恰为14则B胜A负,其他点数不分胜负。对出现胜负的一次投掷,胜一方增1分,负一方减1分。分数先为0分的一方失败。求双方获胜的概率之比
随机过程
随机过程
随机过程是描述随机现象随时间推移而演化的一类数学模型。
• 一族随机变量{X(t),t∈T} ,其中 t 是参数,T 为参数集。
• T 为整数集的随机过程称为随机序列。
Markov 过程
Markov 过程意味着:在已知目前的状态(现在)的条件下,它未来的演变(将来)不依赖于它以往的演变(过去)
对随机序列 {Xn,n=0,1,2⋯}(Xn为有限个或可数个),P(Xn+1=in+1)只与 Xn 有关, 而与 Xn−1,Xn−2,⋯ 无关,则称 {Xn,n=0,1,2⋯} 为 Markov 链。用数学语言描述为:
P(Xn+1=in+1∣Xn=in,Xn−1=in−1,⋯,X0=i0)=P(Xn+1=in+1∣Xn=in)
递推关系
已知A0,An及以下相邻两项之间的递推关系,求An的通项公式。
{A0,AN已知Ah−Ah−1=r(Ah−1−Ah−2),1≤h≤N−1
很简单的高中数列题,我们有:
A0−A1A1−A2A2−A3⋯Ah−Ah+1⋯AN−1−AN=r0(A0−A1)=r1(A0−A1)=r2(A0−A1)=rh(A0−A1)=rN−1(A0−A1)
当r=1时,将上述等式相加,得到:
A0−AN=(1+r+r2+⋯+rN−1)(A0−A1)=1−r1−rN(A0−A1)
将Ah开始的式子相加,得到:
Ah−AN=(rh+rh+1+⋯+rN−1)(A0−A1)=1−rrh−rN(A0−A1)
所以:
A0−ANAh−AN=1−rNrh−rN
因此我们可以得到:
Ah=AN+1−rNA0−AN(rh−rN)=1−rNrh−rNA0+1−rN1−rhAN
当r=1时,将上述等式相加,得到:
A0−AN=N(A0−A1)
将Ah开始的式子相加,得到:
Ah−AN=(N−h)(A0−A1)
所以:
A0−ANAh−AN=NN−h
因此我们可以得到:
Ah=AN+NA0−AN(N−h)=NN−hA0+NhAN
综上所述,我们可以得到:
Ah={1−rNrh−rNA0+1−rN1−rhAN,r=1NN−hA0+NhAN,r=1
赌徒破产问题
一个赌徒在初始时拥有 h 个单位财富。在每局赌博中以概率 p 赢一个单位财富,以概率 q=1−p 输一个单位财富。各局赌博结果独立。当赌徒的财富达到 N 个单位或 0 个单位(破产)时停止赌博。求赌徒破产的概率。
记 Ph 和 Qh 分别为赌徒初始财富为 h 个单位时,财富最终达到 N 个单位的和 0 个单位的概率,显然有初始条件 PN=1 ,P0=0 ,QN=0 ,Q0=1 。
求 Ph
对每一个 Ph ,可以由如下Markov链得到:
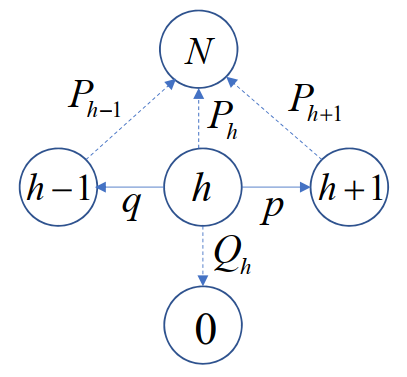
以概率 p 赢一个单位财富,以概率 q=1−p 输一个单位财富
Ph=pPh+1+qPh−1,1≤h≤N−1
我们把这个式子转换为我们刚刚递推公式的形式:
{P0=0,PN=1Ph−Ph+1=pq(Ph−1−Ph),1≤h≤N−1
Ah={1−rNrh−rNA0+1−rN1−rhAN,r=1NN−hA0+NhAN,r=1
其中 r=pq,A0=0,AN=1,Ah=Ph
所以:
Ph=⎩⎨⎧1−(pq)N1−(pq)h,Nh,q=pq=p
求 Qh
设想赌徒与另一位在初始时拥有 N−h 个单位财富的虚拟赌徒赌博。在每局赌博中虚拟赌徒以概率 q 赢一个单位财富,以概率 p 输一个单位财富。赌徒破产时,虚拟赌徒财富达到 N 个单位。
所以真实赌徒从 h 输到破产 就相当于 虚拟赌徒 从 N−h 的赚到 N 个单位,即 Qh=PN−h′
因为Ph′=⎩⎨⎧1−(qp)N1−(qp)h,Nh,p=qp=q,(和 Ph 的输赢概率对调)
所以
Qh=PN−h′=⎩⎨⎧1−(qp)N1−(qp)N−h=(pq)N−1(pq)N−(pq)h,NN−h,p=qp=q
Pascal问题
A,B两人玩一种游戏,初始时两人各有12分。一次掷三枚骰子,若点数恰为11则A胜B负,点数恰为14则B胜A负,其他点数不分胜负。对出现胜负的一次投掷,胜一方增1分,负一方减1分。分数先为0分的一方失败。求双方获胜的概率之比
掷三枚骰子,点数恰为 j 的概率如何计算?我们采用多项式的方法。
=(x+x2+x3+x4+x5+x6)(x+x2+x3+x4+x5+x6)(x+x2+x3+x4+x5+x6)x18+3x17+6x16+10x15+15x14+21x13+25x12+27x11+27x10+25x9+21x8+15x7+10x6+6x5+3x4+x3
总可能性为 63=216 ,所以点数恰为 j 的概率为 216aj ,其中 aj 为上式中 xj 的系数。
一次投掷,A胜的概率为 p=216a11=21627 ,B胜的概率为 q=216a14=21615 ,不分胜负的概率为 1−p−q=2161−a11−a14=216174 。
我们从获胜的角度来看,就是判断从12分到24分的概率。我们可以用Markov链来解决这个问题。
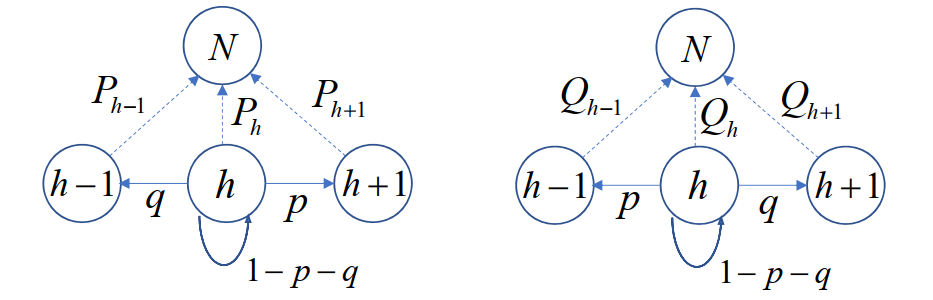
记Ph为A从h分到24分的概率,Qh为B从h分到24分的概率,显然有初始条件P24=1,P0=0,Q24=1,Q0=0。
根据Markov链,我们可以得到如下递推关系:
{PhQh=pPh+1+qPh−1+(1−p−q)Ph,=qQh+1+pQh−1+(1−p−q)Qh,1≤h≤231≤h≤23
即
{Ph−Ph+1Qh−Qh+1=pq(Ph−1−Ph),=qp(Qh−1−Qh),1≤h≤231≤h≤23
⇒{A0,AN已知Ah−Ah−1=r(Ah−1−Ah−2),1≤h≤N−1Ah={1−rNrh−rNA0+1−rN1−rhAN,r=1NN−hA0+NhAN,r=1
所以
Ph=1−(pq)241−(pq)h,Qh=1−(qp)241−(qp)h
代入 h=12 ,得到
P12=1−(pq)241−(pq)12=1−(2715)241−(2715)12=1−3485241−324512=348−524348−324512
Q12=1−(qp)241−(qp)12=1−(1527)241−(1527)12=1−5243481−512324=524−348524−324512
所以
Q12P12=324512−524348−324512=512324=244140625282429536481
显然,A获胜的概率要远大于B获胜的概率。
09 秘书问题
"问题背景"
n位求职者应聘秘书职位,招聘方通过逐个面试予以考察。应聘者的综合能力各不相同,通过面试可给出已面试的应聘者的综合能力大小顺序,且有如下要求。
- 应聘者以某一顺序接受面试,某个应聘者是否被录用必须在他面试结束后立即决定
- 若录用,招聘即告结束,不再面试其他应聘者
- 若不录用,招聘方继续面试下一位应聘者
- 招聘方不得录用曾作出过不录用决定的应聘者
提问:招聘方采用何种策略可使招聘到第一名的应聘者的概率最大?
问题求解
数学描述与假设
为了更好地分析问题,我们给出以下数学描述:
绝对名次:用 j 表示在所有应聘者中居于第 j 名的应聘者,j 为他的绝对名次。第 i 位接受面试的应聘者为 Ai,1≤Ai≤n。Ai=j 表示其绝对名次为 j。
但招聘方在面试的过程中是无法知道每位应聘者的绝对名次的,只知道每位应聘者在面试过程中的局部名次,即相对名次。
相对名次:设Ai 在前 i 位接受面试的应聘者 A1,A2,⋯,Ai 中综合能力名次排名记为 yi,称为他的相对名次,1≤yi≤min{i,Ai}(yi 不会比绝对名次来的大)。
- 我们记相对名次 yi=1 的应聘者称为备选者,备选者是不唯一的。
根据问题背景,招聘方只能根据每位应聘者的相对名次进行决策。
对 1,2,⋯,n 的任一固定排列,应聘者以该排列的顺序面试的概率均为 n!1。
策略 s
由于招聘到绝对名次第一的应聘者的必要条件是录用相对名次第一的备选者。
为了尽可能招到第一名,招聘方应采用“从第 s 位应聘者开始,录用首次出现的一名备选者”的策略 s 来决定录用哪位应聘者。
此时,我们就要去选取更好的 s 使得招聘到第一名的概率最大。
特殊情况
假设目前有 n=4 个人,记上方栏为采用的策略s=1,2,3,4 为绝对排名,侧边栏的每个数字代表参与者的绝对排名。我们将其全排列和采用的策略结果列出来:
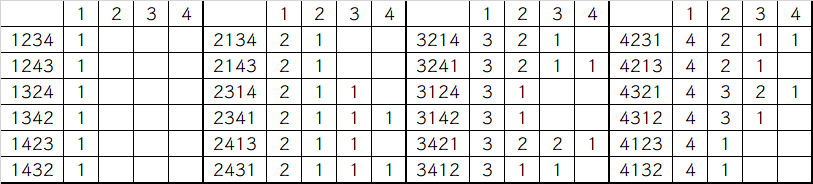
刚开始看的话可能看不懂,我们举 2314 的例子:
- 策略 1:从第 1 位开始录用,此时为
2
- 策略 2:从第 2 位开始录用,此时由于第二位的
3不如第一位的2,所以继续面试下一个,并录用第三位的1
- 策略 3:从第 3 位开始录用,此时由于第三位的
1是备选者,所以录用第三位的1
- 策略 4:从第 4 位开始录用,此时由于第四位的
4不是备选者,而此时又没有面试者了,所以本次招聘失败。
通过上述分析可知,策略 2 在24种可能顺序中有11次可录用到第一名,为最优策略
其实我们通过分析还可以知道,策略 s 就是从第 s 位开始,向后找比前方数字都小的数字,如果找到了就录用,如果没有找到就失败。
记 pn(s)为采用策略 s 录用到第一名的概率。
例如,若采用策略 1 ,则必录取 A1 , pn(1)=n1
为了更好地处理,我们把这个问题分成多个子问题,然后再把子问题的结果合并起来。
记 pnk(s) 为采用策略 s 录用 Ak(k≥s),且 Ak 为第一名的概率。则有
pn(s)=k=s∑npnk(s)
计算 pnk(s)
我们考察每一个 pnk(s) 。经分析可知:
- As,⋯,Ak−1 均不是备选者,否则选不到 Ak
- 前 k−1 位应聘者中的最佳者出现在前 s−1 位应聘者中,否则他将先于 Ak 被录用
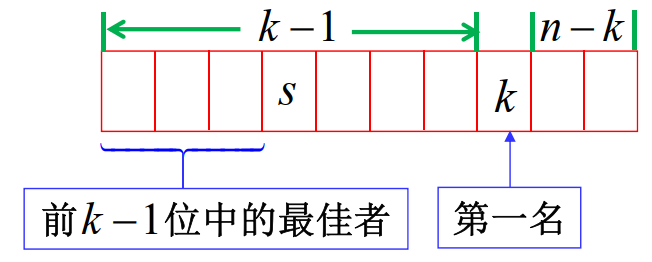
组合方法
我们可以通过组合的方法来计算 pnk(s) 。
假设目前第一名在 k 位上,我们先选取 k−1 个人,并对其进行排列。因为前 k−1 位应聘者中的最佳者要出现在前 s−1 位应聘者中,所以最佳者的可能位置数为 s−1,而其他 k−2 个人没有约束条件,可能位置数为 (k−1)! 。在 k 位之后的人也可以随意排列,其排列数为 (n−k)! 。所以总的可能数有
N=(n−1k−1)(s−1)(k−2)!(n−k)!=(k−1)!(n−k)!(n−1)!(s−1)(k−2)!(n−k)!=(k−1)(n−1)!(s−1)
由此,我们可以得到 pnk(s) 为
pnk(s)=n!N=n!(k−1)(n−1)!(s−1)=n1⋅k−1s−1
概率论方法
我们也可以通过概率论的方法来计算 pnk(s) 。
第一名出现在 k 位上的概率为 n1 ,而前 k−1 位应聘者中的最佳者出现在前 s−1 位应聘者中的概率为 k−1s−1 。所以
pnk(s)=n1⋅k−1s−1
计算 pn(s)
由于 pn(s)=∑k=snpnk(s) ,所以
pn(s)=k=s∑npnk(s)=k=s∑nn1⋅k−1s−1=ns−1⋅k=s∑nk−11=ns−1⋅k=s−1∑n−1k1
我们得到了 pn(s) 的表达式,由于我们希望用策略 s 来招聘到第一名的概率最大,所以我们需要找到最优的 s 使得 pn(s) 最大。
最优策略 s∗
因为 pn(s) 是关于 s 的离散数列,所以我们可以通过隔项相减的方法来求出最优策略。
pn(s)−pn(s−1)pn(s)−pn(s+1)=ns−1⋅k=s−1∑n−1k1−ns−2⋅k=s−2∑n−1k1=ns−1⋅k=s−1∑n−1k1−ns−2⋅(s−21+k=s−1∑n−1k1)=n1⋅k=s−1∑n−1k1−n1=ns−1⋅k=s−1∑n−1k1−ns⋅k=s∑n−1k1=ns−1⋅(s−11+k=s∑n−1k1)−ns⋅k=s∑n−1k1=n1−n1⋅k=s∑n−1k1
分析差值,我们记 s∗ 为使 k=s∑n−1k1<1 的最小的 s ,则
- 当 s≥s∗ 时,则k=s∑n−1k1<1 ,所以 pn(s)−pn(s+1)=n1−n1⋅k=s∑n−1k1>0 ,所以 pn(s∗)>pn(s∗+1)>⋯>pn(n)
- 当 s≤s∗ 时,则k=s−1∑n−1k1≥1 (注意,此时的下标为 s−1 ,其必然小于 s∗ ,所以是 ≥ ) ,所以 pn(s)−pn(s−1)=n1⋅k=s−1∑n−1k1−n1>0 ,所以 pn(s∗)>pn(s∗−1)>⋯>pn(1)
所以当 s=s∗ 时,pn(s) 取得最大值,此时的 s 是最优策略。
最优策略的上下界
我们已知
k=s∗∑n−1k1<1;k=s∗−1∑n−1k1≥1
尝试将其放缩为可以逐项相消求和的形式,我们引入不等式:
∫kk+1x1dx+21(k1−k+11)<k1<∫k−21k+21x1dx
"证明不等式"
左侧不等式:
∫kk+1x1dx+21(k1−k+11)<k1
通过下图。 红斜线的表示 ∫kk+1x1dx ,绿色的表示 21(k1−k+11) ,红色大框里的就是 k1 。因为 x1是凸函数,显然有红斜线的面积加上绿色的面积红色大框里的面积小于红色大框里的面积。
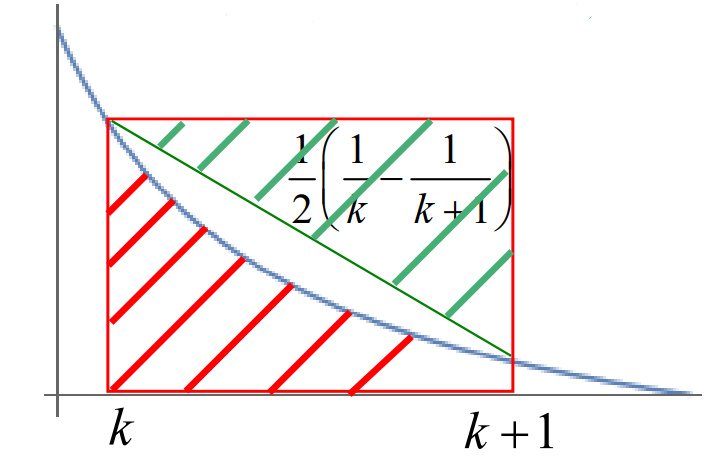
右侧不等式:
这边就不能通过图形来证明了,我们就用最基本的方法来计算:
要证:
⇔(令t=k1∈(0,1])⇔k1<∫k−21k+21x1dx(k≥1)k1<ln(k+21)−ln(k−21)=ln2k−12k+1t<ln2−t2+t=ln(2−t4−1)
记 g(t)=t−ln(2−t4−1) ,则 g′(t)=1−(2−t)24⋅2+t2−t=t2−4t2<0 ,所以 g(t) 单调递减,所以 g(t)<g(0)=0−ln1=0 ,所以 t<ln2−t2+t ,因此 k1<∫k−21k+21x1dx ,得证。
对1≤k=s∗−1∑n−1,有:
1≤k=s∗−1∑n−1k1<k=s∗−1∑n−1∫k−21k+21x1dx=∫s∗−23n−21x1dx=ln(2s∗−32n−1)
我们可以得出 s∗ 的上界为
s∗<e1(n−21)+23
对 1≤k=s∗∑n−1,有:
1>k=s∗∑n−1k1⇒e>k=s∗∑n−1∫kk+1x1dx+21(s∗1−n1)=∫s∗nx1dx+21(s∗1−n1)=ln(s∗n)+21(s∗1−n1)>s∗ne21(s∗1−n1)>s∗n(1+21(s∗1−n1))>s∗n(1+21(e1(n1−21)+231−n1))
所以 s∗ 的下界为
s∗>en(1+21(e1(n1−21)+231−n1))=e1(n−21)+21−2(2n+3e−1)3e−1
综上,我们得到了 s∗ 的上下界:
e1(n−21)+21−2(2n+3e−1)3e−1<s∗<e1(n−21)+23
上下界的差距不超过 1+2(2n+3e−1)3e−1≈1+n+1.791.79 ,当 n 足够大时,上下界的差距趋近于 1 。
且
n→∞limns∗=e1
pn(s∗) 的渐进性质
因为 pn(s∗)=ns∗−1⋅k=s∗−1∑n−1k1 ,且
ln(s∗−1n)=∫s∗−1nx1dx<k=s∗−1∑n−1k1<∫s∗−21n−21x1dx=ln(2s∗−12n−1)
所以
ns∗−1⋅ln(s∗−1n)<ns∗−1⋅k=s∗−1∑n−1k1<ns∗−1⋅ln(2s∗−12n−1)
因为n→∞limns∗=e1,我们有
n→∞limns∗−1⋅ln(s∗−1n)=n→∞limns∗−1⋅ln(2s∗−12n−1)=e1
所以n→∞limpn(s∗)=e1
变式 1 分布不均
"问题背景"
如果 Ai 不再是上文的均匀分布,而是另一种已知的分布,那么招聘方录用一位应聘者时,应采用何种策略?
变式 2 双保险
"问题背景"
招聘方可录用两名应聘者,但对每位应聘者聘用与否的决定仍需在该应聘者面试结束时给出,此时招聘方采用何种策略可使招聘到第一名的应聘者的概率最大?
我们记策略 (r,s) 为:
- 录用自 Ar 起首次出现的一名备选者
- 若已录用一人,录用不早于 As的一名备选者
那么,采用策略 (r,s) 录用到第一名的可能情形
- 第一名是第一个被录用者
- 第一名是第二个被录用者,且第一个被录用者先于 As
- 第一名是第二个被录用者,且第一个被录用者不早于 As
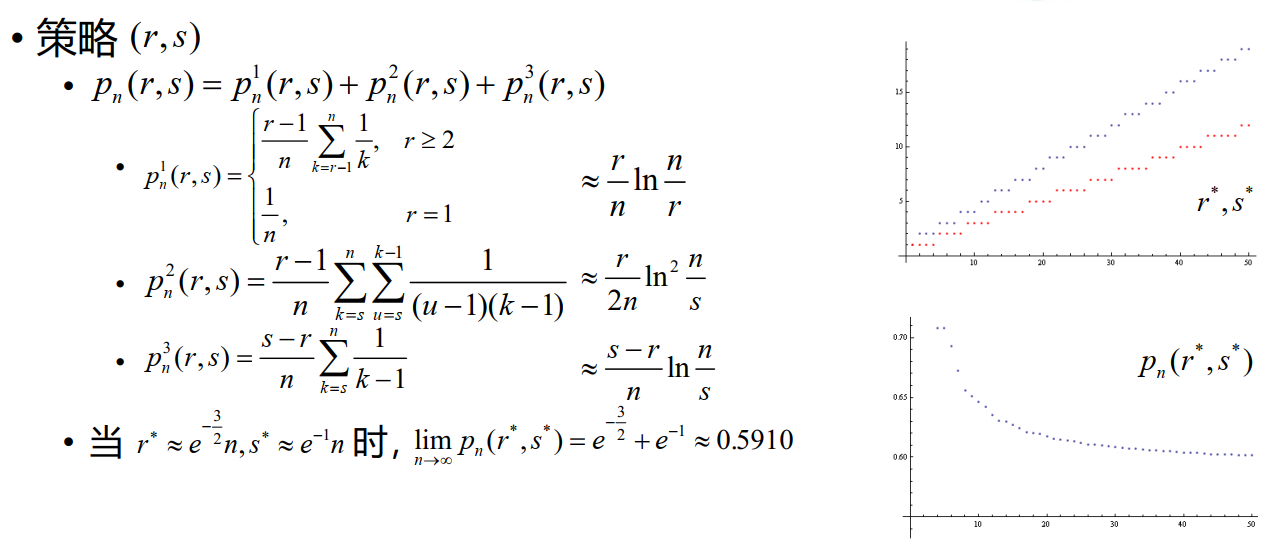
变式 3 期望策略
"问题背景"
招聘方录用一名应聘者,此时招聘方采用何种策略可使录用者的绝对名次的期望值尽可能小?
问题求解
此时就不要求一定要录用备选者了,只要期望值最小即可。
我们记 录用相对名次为 yi=j 的应聘者 Ai 情况下,其绝对名次的期望值为
E(Ai∣yi=j)=k=1∑nk⋅P(Ai=k∣yi=j)=k=1∑nk⋅P(yi=j)P(Ai=k,yi=j)
分析式子中的两个概率:
分母:P(yi=j)=i1
分子:P(Ai=k,yi=j)=P(yi=j∣Ai=k)⋅P(Ai=k)
graph LR
A1[Ai=k] --> B1[k-1个好于k]
A1[Ai=k] --> B2[n-k个不如k]
B1[k-1个好于k] --> C1[j-1个在前i-1中]
B1[k-1个好于k] --> C2[k-j个在后n-i中]
B2[n-k个不如k] --> C3[i-j个在前i-1中]
B2[n-k个不如k] --> C4[n-k-i+j个在后n-i中]
所以在 Ai=k ,j≤k 的条件下,我们对前 i−1 进行选择,选择k−1中的j−1个,选择n−k中的i−j个,即(k−1j−1)(n−ki−j)种可能。再对前i−1个和后n−i个分别进行全排列,即(i−1)!(n−i)!种可能。而总的可能情况为(n−1)!种(我们已经确定了Ai=k,只剩下n−1个人需要排列)。所以
P(yi=j∣Ai=k)=(n−1)!(k−1j−1)(n−ki−j)(i−1)!(n−i)!
又P(Ai=k)=n1,所以
P(Ai=k,yi=j)=(n−1)!(k−1j−1)(n−ki−j)(i−1)!(n−i)!⋅n1=n!(k−1j−1)(n−ki−j)(i−1)!(n−i)!=i(ni)(k−1j−1)(n−ki−j)
如果 j>k ,则 P(Ai=k,yi=j)=0 ,
所以
E(Ai∣yi=j)=k=1∑nk⋅P(yi=j)P(Ai=k,yi=j)=k=j∑nk⋅i(ni)(k−1j−1)(n−ki−j)⋅i=k=j∑nk⋅(ni)(k−1j−1)(n−ki−j)=k=j∑nj⋅(ni)(kj)(n−ki−j)=(ni)jk=j∑n(kj)(n−ki−j)
k(k−1j−1)=j(kj)
组合恒等式
如何对上式进行化简呢?我们先举一些组合恒等式的例子:
k∑(kr)(n−ks)=(nr+s),integer n.k∑(m+kr)(n+ks)=(r−m+nr+s),integer m,integer n,integer r≥0.k∑(kr)(ns+k)(−1)r−k=(n−rs),integer n,integer r≥0.k=0∑(mr−k)(k−ts)(−1)k−t=(r−t−mr−t−s),integer t≥0, integer r≥0, integer m≥0.k=0∑r(mr−k)(ns+k)=(m+n+1r+s+1),integer n≥integer s≥0, integer m≥0, integer r≥0.k≥0∑(kr−tk)(n−ks−t(n−k))r−tkr=(nr+s−tn),integer n.
我们可以用生成函数来解决组合恒等式的问题,例如:
1−x1(1−x)p+11=1+x+x2+x3+⋯=l=0∑∞xl=l=0∑∞p!(l+p)(l+p−1)⋯(l+1)xl=l=0∑∞(pl+p)xl即上式的p阶导数
所以
(1−x)i+21⇒l=0∑∞(i+1l+i+1)xl=(1−x)j+11⋅(1−x)i−j+11=l=0∑∞(jl+j)xl⋅l=0∑∞(i−jl+i−j)xl
因为两端的 xn−i 的系数相等,所以
(i+1n+1)=k=0∑i(jk+j)(i−jn−k−j)=k=j∑i(jk)(i−jn−k)
期望计算结果
所以
E(Ai∣yi=j)=(ni)jk=j∑n(kj)(n−ki−j)=(ni)j(i+1n+1)=i+1n+1j
动态规划
令 U(j,i) 为面试相对名次 yi=j 的 Ai 时可能取得的最优绝对名次期望值。这意味着自首位应聘者面试起,招聘方采用正确决策所能得到的最优绝对名次期望值为 U(1,1) 。
根据 U 之间的关系,我们有如下流程图:
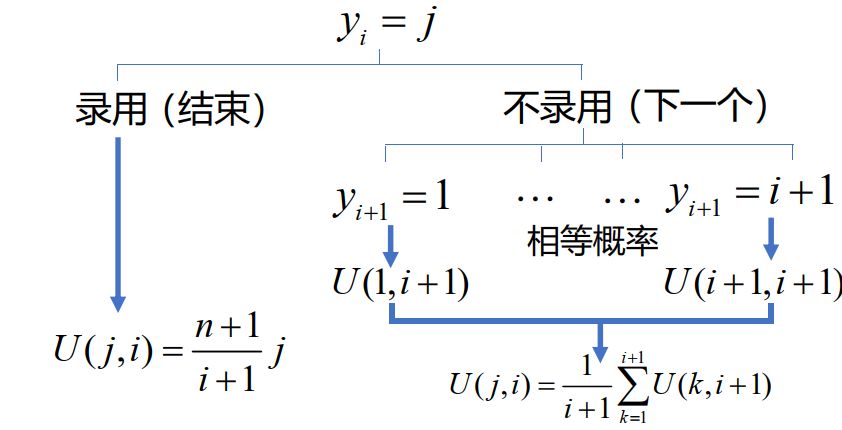
取
U(j,i)=min{i+1n+1j,i+11k=1∑i+1U(k,i+1)}
面试 An 时,相对名次即为绝对名次,招聘方必定录用,那么我们有 U 的末端条件U(j,n)=j。
"举个例子"
有四个人前来面试,他们的绝对名次分别为 1,2,3,4(顺序是无所谓的,末端顺序的作用只体现在前一项的“平均”) ,那么我们可以得到如下的表格:
| U(j,i) |
i=1 |
i=2 |
i=3 |
i=4 |
| j=1 |
min{25⋅1,815}=815 |
min{35⋅1,1225}=35 |
min{45⋅1,25}=45 |
4 |
| j=2 |
|
min{35⋅2,1225}=1225 |
min{45⋅2,25}=25 |
1 |
| j=3 |
|
|
min{45⋅3,25}=25 |
3 |
| j=4 |
|
|
|
2 |
| i+11k=1∑i+1U(k,i+1) |
815 |
1225 |
25 |
|
从上表中可以看出,招聘方采用正确决策所能得到的最优绝对名次期望值为 815 。
所以,给定 n ,我们就能求出招聘方采用正确决策所能得到的最优绝对名次期望值为 U(1,1) 。
策略
记 Ci=i+11k=1∑i+1U(k,i+1) ,则 U(j,i)=min{i+1n+1j,Ci} 。
为让 U(j,i) 尽可能小,我们需要让 i+1n+1j 和 Ci 进行比较,取得小值。所以当 i+1n+1j<Ci ,即 j<Ci⋅n+1i+1 时,我们应该录用 Ai 。否则,继续面试。
此时的策略 si=⌊Ci⋅n+1i+1⌋ 。
动态规划的思想是从末端开始,逐步向前推进,每一步都是最优的。所以我们可以从末端开始,逐步向前推进,每一步都更改策略,且是最优的。
根据每一步的策略,我们可以给出 Ci 的递推式:
Ci−1=i1k=1∑iU(k,i)=i1k=1∑imin{i+1n+1k,Ci}=i1(i+1n+1k=1∑sik+k=si+1∑iCi)=i1(i+1n+12si(si+1)+(i−si)Ci)
尾部条件为 Cn−1=n1k=1∑nU(k,n)=n1k=1∑nk=2n+1
所以我们可以通过递推式来求出 Ci ,然后再求出 si ,最后求出 U(1,1) 。
变式 4 分布不均的期望策略
"问题背景"
如果 Ai 不再是变式3的均匀分布,而是另一种已知的分布,那么招聘方录用一位应聘者时,应采用何种策略使得录用者的绝对名次的期望值尽可能小?
问题推广
"问题背景"
- 招聘方录用一位应聘者,采用何种策略可使他为第 k 名的概率尽可能大
- 招聘方录用一位应聘者,采用何种策略可使他为前 k 名的概率尽可能大
- 招聘方录用 k 位应聘者,采用何种策略可使其中包含第一名的概率尽可能大
- 应聘者数目为一随机变量
10 安全观演
"问题背景"
广场某处正在进行一场露天表演,若干人先后到达附近并选择一个地点观看表演。
- 观众选择地点有如下要求:
- 与舞台中心的距离不小于 L
- 与之前到达的任一观众的距离不小于 r
- 在满足上述要求的情况下,观众选择与舞台中心距离最近的某个点
- 观众选择地点的方式有两种:
- 有引导:观众在工作人员引导下到达满足要求的地点
- 无引导:观众自行选择满足要求的地点
提问,第 n 个到达的观众与舞台中心的距离 dn 大概是多少?
"题源:阿里巴巴数学竞赛"

记舞台中心为 O 。以 O 为圆心,半径为 L 的圆为 C,记第 i 个到达的观众为 Ai ,所选位置为 Pi 。以 Pi 为圆心,r 为半径的圆为 Ci,我们有
- di=∣OPi∣≥L
- Pi 不在圆 C 内,也不在圆 C1,C2⋯Ci−1内
- d1≤d2≤⋯≤dn,否则若 di>di+1,则 Ai 到达时可选择 di+1 ,矛盾
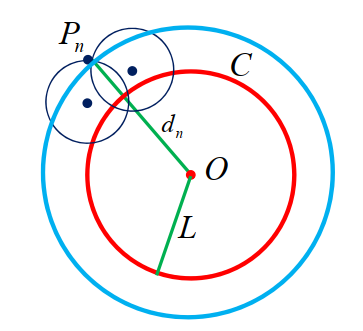
观演距离上界
观众 An 无法选到与点 O 距离小于 dn 的点,也就是说,以 O 为圆心,半径为 dn 的园内的所有店均在圆 C 或 C1,C2⋯Cn−1 内。因此:
π⋅dn2⇒dn≤πL2+(n−1)⋅πr2≤L2+(n−1)r2
"阿里巴巴 2(1) 上界"
此时 r=1,L=10 ,所以 dn≤102+(n−1)12=99+n≤100n=10n
观演距离下界
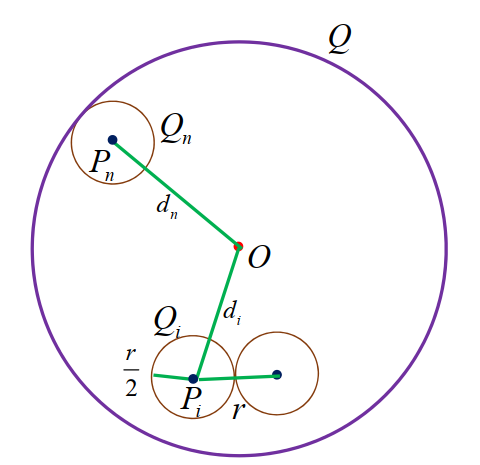
记以 Pi 为圆心,2r 为半径的圆为 Qi,则 Q1,Q2⋯Qn−1 两两不相交,且均在以 O 为圆心,半径为 dn+2r 的圆内。因此:
π⋅(dn+2r)2⇒dn≥n⋅π⋅(2r)2≥(2n−21)⋅r
"阿里巴巴 2(1) 下界"
此时 r=1,L=10 ,所以 n≥2 时, dn≥(2n−21)⋅1≥2n−52n=10n。
n=1 时,d1=10,不等式仍然成立。
所以 2(1) 选B。
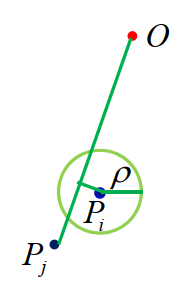
考虑遮挡
若以 Pi 为圆心,ρ 为半径的圆周与线段 OPj 相交,则 Aj 会被 Ai 遮挡。如下图所示:
圆周引导 - 无遮人数的上界
如果在工作人员引导下,人们都恰好站在圆周 C 上,即:
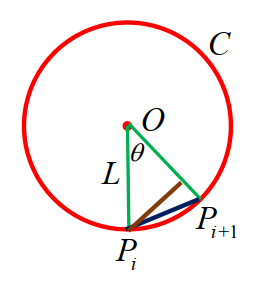
此时每个人排在C的内接正 n 边形的顶点上,所以 θ=n2π,且 n 需满足下列条件:
∣PiPi+1∣dPi,OPi+1=2L⋅sin2θ=2L⋅sinnπ≥r=L⋅sinθ=L⋅sinn2π≥ρ
最优引导 - 无遮人数的上界
最优的时候就不该是圆周:
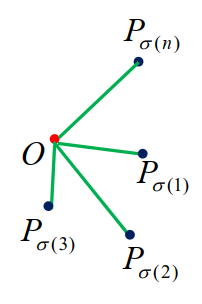
n 条线段在点 C 将周角分为 n 个角 ∠Pσ(i)O∠Pσ(i+1),这里 σ(1),σ(2),..,σ(n)是1,2,..,n 的一个排列,并记σ(n+1)=σ(1),则有i=1∑n∠Pσ(i)O∠Pσ(i+1)=2π,且:
sin∠Pσ(i)O∠Pσ(i+1)≥2ρ(dσ(i)1+dσ(i+1)1)
否则,不妨设dσ(i)≤dσ(i+1),则
dσ(i)sin∠Pσ(i)O∠Pσ(i+1)<dσ(i)2ρ(dσ(i)1+dσ(i+1)1)≤dσ(i)2ρdσ(i)2=ρ
将产生遮挡。
所以
2π=i=1∑n∠Pσ(i)O∠Pσ(i+1)≥i=1∑nsin∠Pσ(i)O∠Pσ(i+1)≥2ρi=1∑n(dσ(i)1+dσ(i+1)1)=ρi=1∑ndi1
又因为观演距离的上界为 dn≤L2+(n−1)r2,所以:
2π⇒ρπr+rL⇒ρ2π2r2+ρ2πL+r2L2⇒n≥ρi=1∑ndi1≥ρi=1∑nL2+(i−1)r21≥ρi=1∑n∫ii+1L2+(x−1)r2dx=ρ∫1n+1L2+(x−1)r2dx=r2ρ∫1n+12(rL)2+(x−1)d((rL)2+(x−1))=r2ρ((rL)2+(n+1−1)−(rL)2+(1−1))=r2ρ((rL)2+n−rL)≥(rL)2+n≥(rL)2+n≤ρ2π2r2+ρ2πL
"第三行"
"阿里巴巴 2(2) "
此时 r=1,L=10,ρ=1/6 ,所以 n≤ρ2π2r2+ρ2πL=1/36π2+1/62π⋅10=36π2+120π≈732.3。
所以 2(2) 选B。
11 蛛网模型
"问题背景"
如何解释某些生产周期较长的商品在失去均衡时发生的不同波动情况?
差分方程
设 y(n)=yn,是依赖于整数变量 n=0,±1,±2,⋯ 的函数,则称Δy(n)=y(n+1)−y(n) 为 y(n) 的一阶差分,Δ2y(n)=Δ[Δy(n)]=Δy(n+1)−Δy(n) 为 y(n) 的二阶差分,以此类推,Δky(n) 为 y(n) 的 k 阶差分。
含有未知函数的有限差分的方程称为差分方程:
F(n,yn,Δyn,Δ2yn,⋯,Δkyn)=0
如果将 Δyn 等同于 yn+1−yn,将 Δ2yn 等同于 yn+2−2yn+1+yn,以此类推,将 Δkyn 等同于 yn+k−kyn+k−1+⋯+(−1)kyn,则上式可写成
F(n,yn,yn+1,⋯,yn+k)=0
所以差分方程本质上就是数列的递推。
m 阶线性差分方程表示为:
am(n)yn+m+am−1(n)yn+m−1+⋯+a1(n)yn+1+a0(n)yn=fn
- 齐次:fn=0
- 常系数:ai(n)=ai(i=0,1,⋯,m)
二阶线性常系数齐次差分方程的解
二阶线性常系数齐次差分方程表示为
xn+2+a1xn+1+a2xn=0
若 xn=f(n)是差分方程的解,则 xn=cf(n) 也是差分方程的解;若 xn=f(n) 和 xn=g(n) 都是差分方程的解,则 xn=f(n)+g(n) 也是差分方程的解。
若 xn=λn 是差分方程的解,则
λn+2+a1λn+1+a2λn=0
即(计算非零解)
λ2+a1λ+a2=0
称为差分方程的特征方程,它的根称为差分方程的特征根。
若特征方程有两个不同的实根 λ1 和 λ2,则 xn=c1λ1n+c2λ2n 是差分方程的解。
若特征方程有两个相等的实根 λ,则 xn=c1λn+c2nλn 是差分方程的解。
经济学与经济模型
经济学是研究人类社会各个发展阶段之各种经济活动、经济关系、经济运行
规律的科学
经济数学模型是广泛用于经济研究、经济分析的数学模型。是用数学形式,对经济理论假说进行数量化,以探讨客观经济过程的本质联系及其规律的一种经济研究与管理的工具。
微观经济学
微观经济学通过对个体经济单位的经济行为的分析,说明在现代经济社会中市场机制的运行及其对经济资源的配置
商品、货币与价格
商品(commodities):在社会分工的体系中,经济上相互独立的生产者所生产的、以自己的属性满足人的某种需要、为他人(即为社会)消费、通过交换进入把它当作使用价值的人的手里的劳动产品和服务。
货币(money):在商品交换中逐渐分离出来的固定地充当一般等价物的特殊商品。是价值量发展到一般价值形式的产物。
价格(price):市场经济和商品交换中最常用的范畴,是商品与货币交换的比例,直接表明单位商品交换价值的实际货币量。
需求
一种商品的需求是消费者在一定时期内在各种可能的价格水平下,愿意并且能够购买的该商品的数量。
决定需求数量的主要因素有商品的价格、消费者的收入水平、相关商品的价格(最基本的因素)、消费者的偏好、消费者对该商品的价格预期。
需求函数表示一种商品的需求数量和影响该需求数量的各种因素之间的相互关系(往往是减函数)
Qd=f(P)
其中 Qd 表示需求数量,P 表示商品的价格。
我们往往用其反函数 P=f−1(Qd) 来表示需求函数。
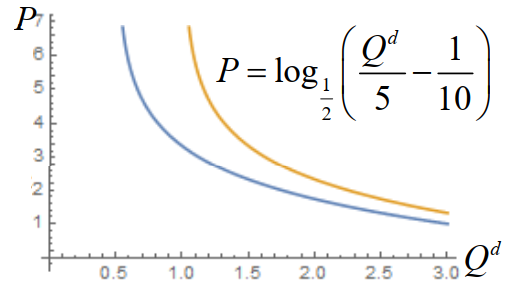
- 需求量的变动:其他条件不变,由价格的变动所引起
- 需求的变动:价格不变,由其他因素变动所引起
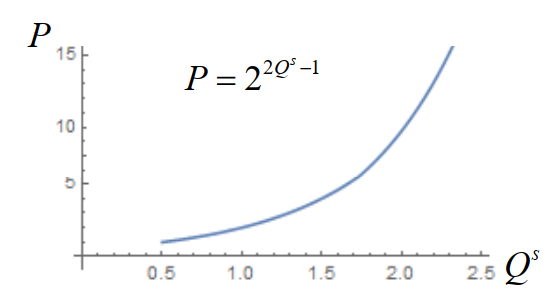
供给
一种商品的供给是指生产者在一定时期内在各种可能的价格水平下,愿意并且能够提供出售的该商品的数量。
决定供给数量的主要因素有商品的价格、生产的成本、相关商品的价格、生产的技术水平、生产者对未来的价格预期。
供给函数表示一种商品的供给量与影响该商品供给量的各种因素之间的相互关系(往往是增函数)
Qs=f(P)
其中 Qs 表示供给数量,P 表示商品的价格。
我们往往用其反函数 P=f−1(Qs) 来表示供给函数。
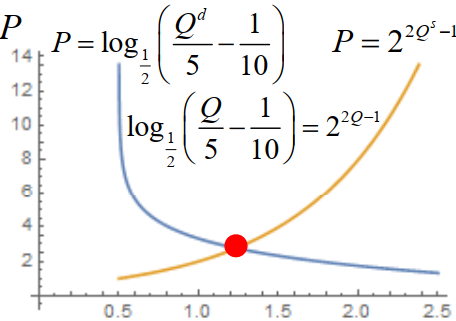
均衡
经济学中的均衡指经济系统中变动着的各种力量在相互作用之后所
达到的“平衡”状态,即相对静止状态。如果没有外界扰动因素,这种状态会持续下去。
均衡价格是市场上某种商品的需求量和供给量相等时的价格。均衡价格水平下的相等的供求数量称为均衡数量。
均衡价格是市场上商品的需求和供给这两种相反力量共同作用的结果,是在市场供求力量自发作用下形成的。一旦市场价格偏离均衡价格,需求量和供给量就会出现不一致的非均衡状态,这种非均衡状态在市场机制的作用下会逐步消失,从而恢复到均衡价格水平。
动态模型
静态与动态
静态模型与静态分析:
- 变量没有时间先后的差别
- 变量的调整时间被假设为零
- 考察既定条件下变量相互作用下所呈现的状态
动态模型与动态分析:
- 区分变量在时间上的先后差别
- 研究不同时点上变量之间的相互关系
- 考察不同时点上变量的相互作用在状态形成和变化过程中所起的作用和在时间变化过程中状态的实际变化过程
动态均衡价格模型
对生产周期较长的商品,商品的供给量通常由前一生产周期的价格决定:
Qns=g(Pn−1)
但需求还是由当前价格决定:
Qnd=f(Pn)
因此,均衡价格模型为:
Qns=g(Pn−1)=Qnd=f(Pn)
"有如下的情况"
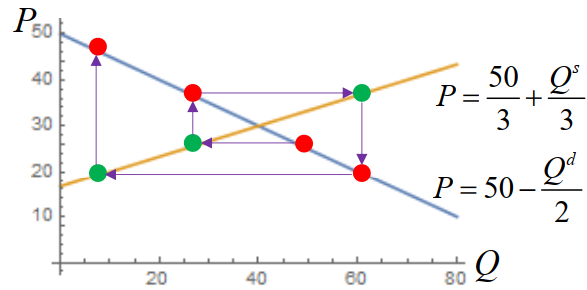
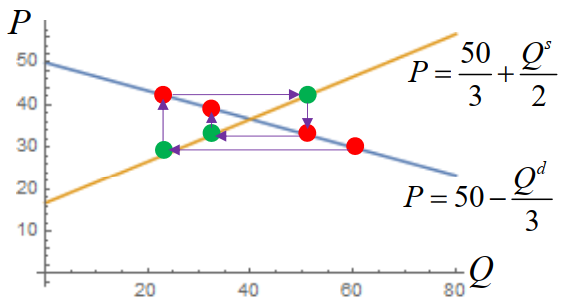
上图长得像蛛网,因此称为蛛网模型。
蛛网模型
蛛网模型是研究某些生产周期较长且不宜储存的商品均衡价格的动态稳定性的模型
- 当商品的市场实际价格偏离均衡价格后,在市场机制的作用下,实际价格是否能回到原有的均衡价格水平,即均衡价格是否动态稳定,并考察它所需要具备的条件
记在周期 n 中,某种商品的供求量为 xn,价格为 yn
这里的供求量是指周期 n 中的供给量与需求量,此时的供给量是由周期 n−1 的价格决定的,需求量是由周期 n 的价格决定的,设此时二者相等。
- 需求由当前价格决定,有需求函数 xn=f(yn),其反函数为 yn=h(xn)
- 供给由周期 n−1 的价格决定,有供给函数 xn+1=g(yn)
- 均衡点 (x0,y0) 满足 x0=g(y0) 和 y0=h(x0),即需求函数与供给函数的交点
假设需求函数与供给函数为线性函数,其过均衡点 (x0,y0) 的方程为
yn−y0=−α(xn−x0),xn+1−x0=β(yn−y0)
其中,α 是商品需求量减少一个单位时价格的上涨量,1/α 是商品价格上涨一个单位时需求量的减少量。β 是商品价格上涨一个单位时(下一周期)供给量的增加量。
由此可得,递推关系为
xn+1−x0=β(yn−y0)=−αβ(xn−x0)
所以
xn−x0=(−αβ)n−1(x1−x0)
所以,数列 {xn} 收敛的充要条件为 αβ<1。
若需求函数 h 或供给函数 g 不为线性函数,可在均衡点附近用线性函数近似,即令 a=−h′(x0) 与 b=g′(y0)。
均衡的稳定性
当一个均衡价格体系在受到干扰而偏离均衡点时,如果这个体系在市场机制的作用下能回到均衡点,则称这个均衡价格体系是稳定均衡,否则是不稳定均衡。
根据以上分析,均衡价格体系的稳定性取决于 αβ 的大小,我们可以得到三种情况:
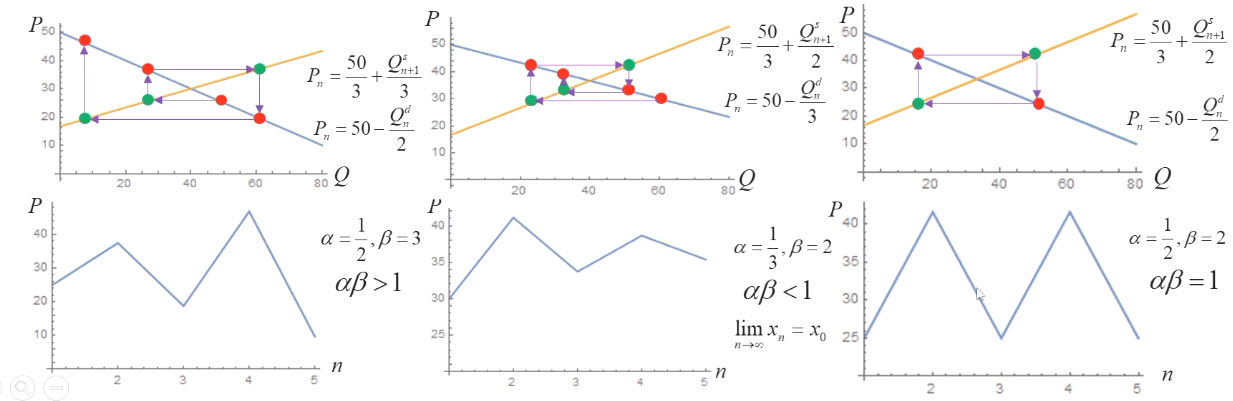
改进的蛛网模型
假设商品的供求量由前两个周期的价格决定
- 记需求函数为 xn=f(yn),其反函数为 yn=h(xn)
- 记供给函数为 xn+2=g2(yn+1,yn)
- 供给函数简化为 xn+2=g(2yn+1+yn),即供给量由前两个周期的价格的平均值决定
- 均衡点 (x0,y0) 满足 y0=h(x0) 和 x0=g(y0)
假设需求函数与供给函数为线性函数,其过均衡点 (x0,y0) 的方程为
yn−y0=−α(xn−x0),xn+2−x0=β(2yn+1+yn−y0)
则递推关系为
2xn+2−2x0=β(yn+1+yn−2y0)=β(yn+1−y0+yn−y0)=β(−α(xn+1−x0)−α(xn−x0))
记 zn=xn−x0,则
2zn+2=−αβ(zn+1+zn)
可以发现 n→∞limzn=0 当且仅当 n→∞limxn=x0。
通项求解
我们现在得到了差分方程
2zn+2+αβzn+1+αβzn=0
其特征方程为
2λ2+αβλ+αβ=0
解得
λ1=4−αβ+α2β2−8αβ,λ2=4−αβ−α2β2−8αβ
- λ1 和 λ2 可以是虚数
要使得 n→∞limzn=0,则 λ1 和 λ2 的模都小于 1,即
- αβ≥8 时,λ1 和 λ2 都是实数,此时λ2=4−αβ−α2β2−8αβ<4−αβ<−1,所以不收敛
- 0<αβ<8 时,λ1 和 λ2 都是复数,此时 λ1,2=4−αβ±48αβ−α2β2i,其模 ∣λ1,2∣=(4−αβ)2+(48αβ−α2β2)2=48αβ。
- 所以当 0<αβ<2 时,n→∞limzn=0,即 n→∞limxn=x0,此时均衡价格是稳定的;
- 当 2<αβ 时,n→∞limzn=0,即 n→∞limxn=x0,此时均衡价格是不稳定的。
与供给量由前一个周期的价格决定相比,价格体系是稳定均衡的条件有所放宽。
12 种群增长模型
"问题背景"
一种生物种群的增长过程,可以用一个差分方程来描述。假设种群的增长率与种群数量成正比,且种群的增长受到环境的限制,即种群的增长率随种群数量的增加而减小,那么种群的增长率应该是种群数量的函数。试建立种群增长模型,分析种群的增长规律。
生态学概念
**生态学(ecology)**是研究生物与环境及生物与生物之间相互关系的生物学分支学科。其主要研究对象为:
- 种群(population):同种生物在一定空间范围内同时生活着所有个体的集群
- 生物群落(biological community):生活在一定生境中全部物种及其相互作用、彼此影响所构成的整体
- 生态系统(ecosystem):一定空间中的生物群落与其环境组成的系统,其中各成员借助能流和物质循环,形成一个有组织的功能复合体
种群动态(population dynamics) 表示种群的消长以及种群消长与种群参数(如出生、死亡、迁入、迁出等)间的数量关系
离散单种种群模型
假设现实种群只由一个世代构成,相继世代之间没有重叠,那么每一代的个体数量只与上一代的个体数量有关,这样的种群称为单种种群(single-species population)。
记 xn 为第 n 代个体数量,数列{xn} 满足递推关系式:
xn+1=f(xn)
指数增长模型
每一代个体繁殖的个体数量与该代个体数量之比是一个常数
xnxn+1=r
所以
xn=rnx0
其中,r 为增长率(growth rate),x0 为初始个体数量
指数增长模型不适于描述较长时期的人口演变过程,但某地一个较短时间内的人口统计数据可能符合指数增长模型
Logistic模型
考虑到种群的增长受到环境的限制,即种群的增长率随种群数量的增加而减小,因此,种群的增长率应该是种群数量的函数,即
xn+1=f(xn)=xn+rxn(1−Kxn)
或者
xnΔxn=r(1−Kxn)
其中,K 为环境承载量(carrying capacity),r(≥−1) 为内禀增长率(innate rate of increase)
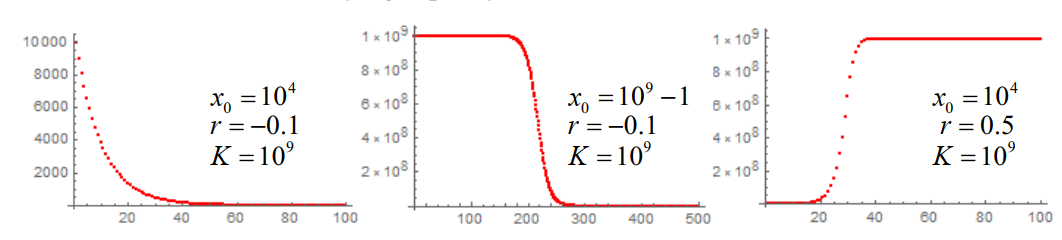
平衡点
差分方程的平衡点是指满足 xn+1=xn 的点,即满足 f(x∗)=x∗ 的点,其中 x∗ 为平衡点。
若只要初始点 x0 与平衡点 x∗ 充分接近,即有 n→∞limxn=x∗,则称平衡点 x∗ 渐近稳定(asymptotically stable)
渐进稳定的判别:
|
渐进稳定 |
不稳定 |
|
∣f′(x∗)∣<1 |
∣f′(x∗)∣ >1 |
| f′(x∗)=1 |
f′′(x∗)=0 且 f′′′(x∗)<0 |
f′′(x∗)=0 且 f′′′(x∗)>0 |
| f′(x∗)=−1 |
−2f′′′(x∗)<3(f′′′(x∗))2 |
−2f′′′(x∗)>3(f′′′(x∗))2 |
| ⋯ |
⋯ |
⋯ |
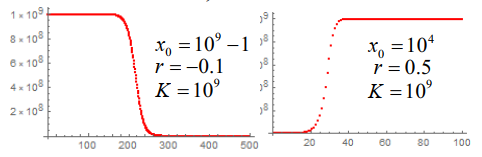
考察 Logistic模型的渐近稳定性,即考察 xn+1=xn+rxn(1−Kxn) 的平衡点 x∗ 的渐近稳定性。取 f(x)=(1+r)x−Krx2。
f(x)=x 的解为 x=0 和 x=K,所以平衡点为 x1∗=0 和 x1∗=K。
f′(x)=1+r−K2rx,所以 f′(0)=1+r,f′(K)=1−r。
- 当 −1≤r<0 时,∣f′(0)∣<1,∣f′(K)∣>1,所以 x1∗=0 渐进稳定,x1∗=K 不稳定
- 当 0<r≤2 时,∣f′(0)∣>1,∣f′(K)∣<1,所以 x1∗=0 不稳定,x1∗=K 渐进稳定
- 当 r>2 时,∣f′(0)∣>1,∣f′(K)∣>1,所以 x1∗=0 不稳定,x1∗=K 不稳定
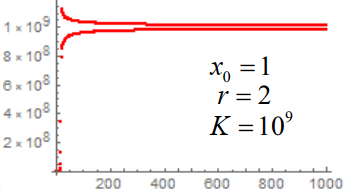
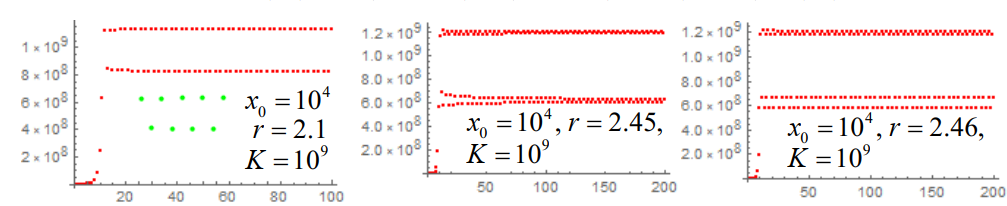
周期点
r>2 时,我们会得到这样的结果:
差分方程 xn+1=f(xn) 的周期点是指满足 fk(x∗)=x∗ 的点,其中 k 为正整数,x∗ 为 k 周期点。这里 fk(x)可通过
以下方式定义:
fk(x)=f(fk−1(x)),f1(x)=f(x)
- 差分方程 xn+1=f(xn) 的 k 周期点即为差分方程 xn+1=fk(xn) 的平衡点,前者的渐进稳定性也由后者决定
Logistic模型的 2-周期点
我们有:
f(x)=(1+r)x−Krx2
且
f2(x)=f(f(x))=(1+r)((1+r)x−Krx2)−Kr((1+r)x−Krx2)2=(1+r)2x−Kr(1+r)(2+r)x2+K22r2(1+r)x3−K3r3x4
因为我们要找的是 2-周期点,所以我们要求解 x=f2(x),即
x=(1+r)2x−Kr(1+r)(2+r)x2+K22r2(1+r)x3−K3r3x4⇒x(Kx−1)(r2(Kx)2−r(r+2)Kx+(r+2))=0⇒x+=2r(r+2)+r2−4K,x−=2r(r+2)−r2−4K
所以,根据2-周期点的性质,我们有f(f(x+))=x+,两边再作用 f,我们有 f(f(f(x+)))=f(x+),所以 f(x+) 也是 2-周期点,又由于我们只有两个 2-周期点,且 x+ 不是平衡点,所以 f(x+)=x−。同理,我们有 f(x−)=x+。
稳定性分析
判断 ∣f2′(x)∣ 是否小于 1,即判断 ∣f′(x+)∣ 和 ∣f′(x−)∣ 是否小于 1。
f2′(x+)=f′(f(x+))f′(x+)=f′(x−)f′(x+)=((1+r)−K2rx−)((1+r)−K2rx+)=(1+r)2−K2r(1+r)(x++x−)+K24r2x+x−=(1+r)2−K2r(1+r)r2r(r+2)K+K24r2r2(r+2)K2=(1+r)2−2(1+r)(r+2)+4(r+2)=5−r2
同理,我们有 f2′(x−)=5−r2。
所以,当 2<r<6 时,∣f2′(x+)∣<1,∣f2′(x−)∣<1,此时 2-周期点是渐进稳定的。
混沌
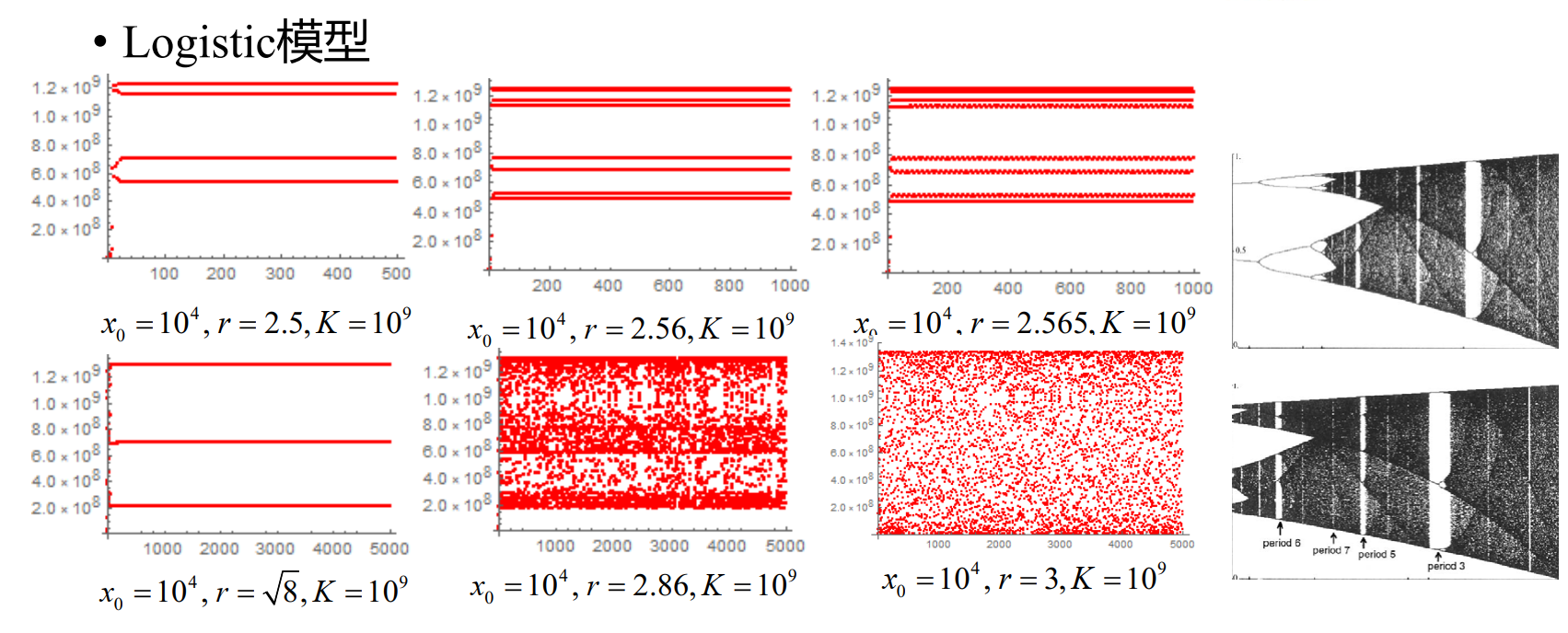
Li-Yorke 定理
若实数轴一区间到其自身的连续函数,有一个 3−周期点,则对任意正整数 k ,f 有一个 k−周期点
Sharkovsky 定理
任意正整数 n 可唯一表示成 n=2s(2p+1),其中s,p∈N。所有正整数可据此排列,称为 S 型排序。
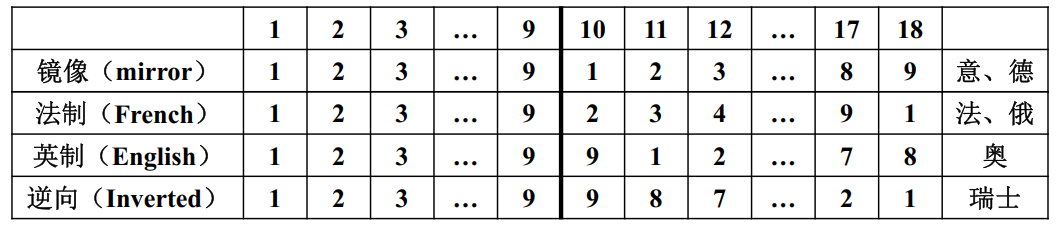
3,5,7,9,11,⋯
2⋅3,2⋅5,2⋅7,2⋅9,2⋅11,⋯
22⋅3,22⋅5,22⋅7,22⋅9,22⋅11,⋯
⋯
2s⋅3,2s⋅5,2s⋅7,2s⋅9,2s⋅11,⋯
⋯
若实数轴一区间到其自身的连续函数 f 具有 k−周期点,在 S 型排序中,如果 k 在 m 的前面,则必有 m 周期点
13 追逐问题
"问题背景"
两艘船在平静的海面上相向而行,海盗船的速度为 vp,商船的速度为 vm
- 两船速度不变。
- 海盗船的航向始终指向商船。
问:海盗船是否能追上商船?追上时,两船的位置分别在哪里?
两船速度不变
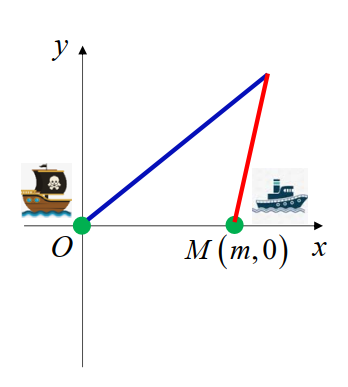
若在某一时刻,海盗船与商船位于同一地点 A(x,y),则∣MO∣∣AO∣=k,即
(x−m)2+y2x2+y2=k
所以 A 的轨迹为圆
(x−k2−1k2m)2+y2=(k2−1km)2

两船速率不变,一船方向改变
商船沿直线航行,航向垂直于连接商船与海盗船初始位置的直线。在任意时刻,海盗船的航行方向为连接商船与海盗船此时位置的直线的方向。
以海盗船初始位置为原点,商船初始位置为 M(m,0),建立直角坐标系,记 vpvm=r。设海盗船在与商船相遇前的轨迹为函数 y=f(x),则
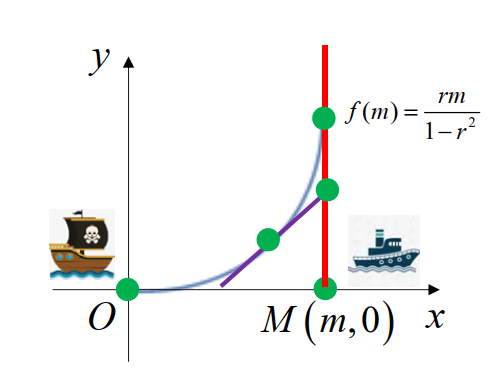
在 t 时刻
- 商船位置 Mt(m,vmt),海盗船位置 Pt(x(t),y(t))
- 连接海盗船与商船当前位置的直线斜率为 x−my−vmt=f′(x)
- 直线方程为 y−vmt=f′(x)(x−m)
- 海盗船的轨迹自原点至 Pt 的弧长为 vpt=∫0x1+f′2(z)dz
所以,我们可以得到
vp1∫0x1+f′2(z)dz=t=vm1(y−(x−m)f′(x))
对两边求导,我们有
vp11+f′2(x)−vpvm1+f′2(x)1+f′2(x)df′(x)lnf′(x)+1+f′2(x)0x⇒lnf′(x)+1+f′2(x)⇒f′(x)+1+f′2(x)=vm1(f′(x)−f′(x)−(x−m)f′′(x))=(x−m)f′′(x)=−x−mrdx=−rln∣x−m∣∣0x=−rln1−mx=(1−mx)−r
对两边取倒数,我们有
{f′(x)+1+f′2(x)f′(x)−1+f′2(x)=(1−mx)−r=(1−mx)r
所以
f′(x)=21((1−mx)−r−(1−mx)r)
对两边积分,我们有
f(x)=1−r2rm+2m−x(1+r1(1−mx)r−1−r1(1−mx)−r)
所以追上时的纵坐标为
f(m)=1−r2rm
同类问题
14 最速降线问题
"问题背景"
给定垂直平面上两点 A,B,一质点以何路径从 A 运动到 B,可使运动时间最短?
直线下降
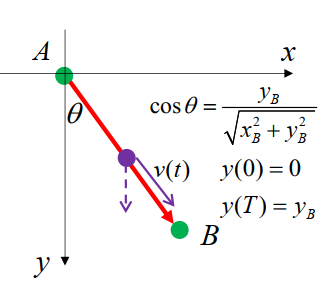
就是斜坡下滑问题,有
21gcosθT2=l
所以
T=gcosθ2l=gxB2+yB2yB2xB2+yB2=gyB2(xB2+yB2)
如果用常微分方程来解,我们有

圆弧下降

最速降线
光
Fermat 原理
光线在两点之间传播的路径是使得两点之间的传播时间最短的路径。
Snell 定律
sinθ2sinθ1=v2v1
可由 Fermat 原理 推出。
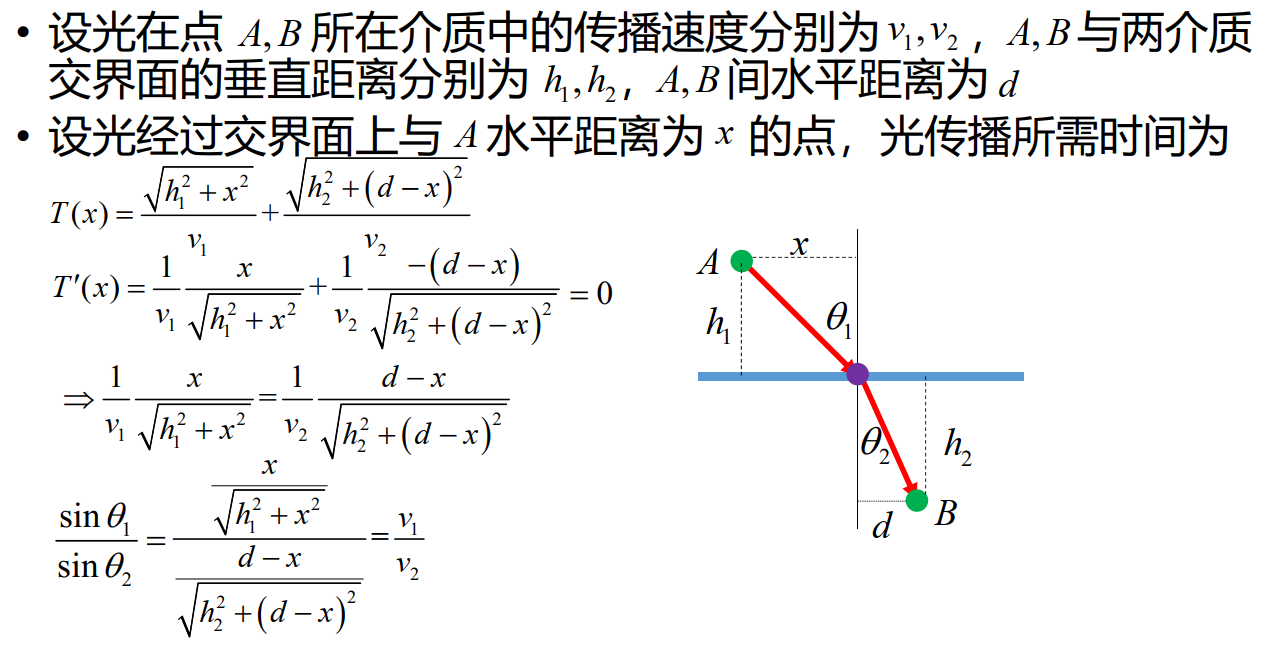
推导最速降线
将平行于 x 轴的直线视作折射率逐渐减小的不同介质的分界面。
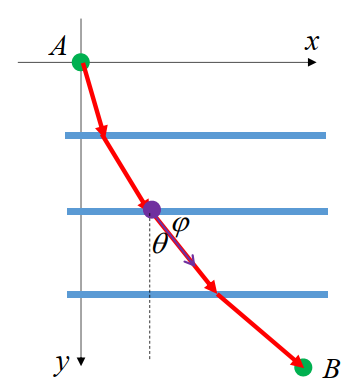
由 Snell 定律,可知 vsinθ 为常数,记
vsinθ=C
因为
sinθ=cosϕ=1+tan2ϕ1=1+y′21
21mv2=mgy⇒v=2gy
所以
vsinθ=1+y′212gy1⇒y′⇒C2−yydy令y=C2sin2β2C2sin2βdβ⇒dx=C=2gCy1−2gCy≜yC2−y=dx,有=dx=C2(1−cos2β)dβ
所以
{xy=R(γ−sinγ)=R(1−cosγ)
或者
x=Rarccos(1−Ry)−y(2R−y)
摆线
实际上,最速降线就是摆线。

变分法
求出最速降线的严格做法——变分法。
变分法是研究泛函的极值的方法
可用 Euler-Lagrange 方程求解。
15 种群数量变化模型
指数增长模型
我们给出假设:
- 环境承载容量无限,所有个体独立生活,彼此间不存在竞争
- 种群处于封闭(closed)状态,不存在迁入(immigration)和迁出(emigration)
- 记人均出生/死亡/增长率为:b,μ,r=b−μ
- 存在常数 b 和 μ,对任意 t ,在自 t 至 t+Δt内,出生的个体数量为 bx(t)Δt,死亡的个体数量为 μx(t)Δt
所以
x(t+Δt)−x(t)=(b−μ)x(t)Δt
即
Δtx(t+Δt)−x(t)=rx(t)⇒dtdx=rx
所以
x(t)=x0ert
指数增长模型不适于描述较长时期的人口演变过程,但某地一个较短时间内的人口统计数据可能符合指数增长模型.
Logistic模型
种群人均增长率仅与种群数量有关,且是种群数量的递减函数:
dtdx=rx(1−Kx)
其中 K 为环境承载量,r 为内禀增长率,x 为种群数量
所以
x(t)=x0+(K−x0)e−rtKx0
性质
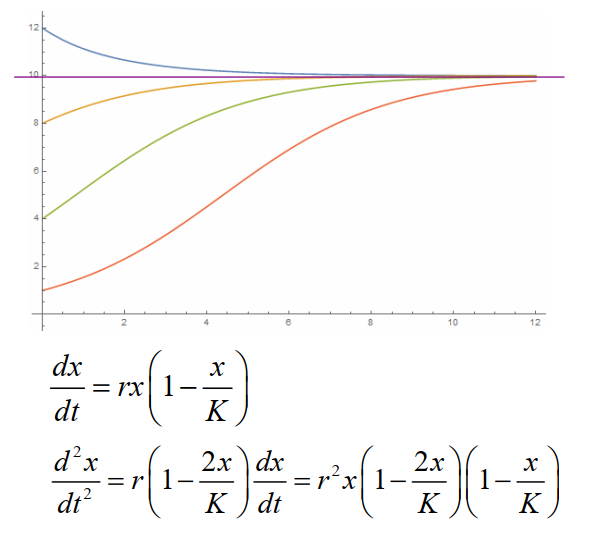
- 当 0<x(0)<K 时,种群数量随时间单调递增;当 x0>K 时,种群数量随时间单调递减;当 x0=K 时,种群数量保持不变。
- x(t) 在 t=21K 时有拐点。
- 当 r<0 时,种群数量随时间单调递减至 0;当 r>0 时,种群数量随时间单调递增至 K;当 r=0 时,种群数量保持不变。
小总结
多数情况下,指数模型与 Logistic 模型并不是基于生物学机理,而是一种经验模型模型及其参数应根据实际数据进行估计和检验
除此之外,还有很多别的模型,如
dtdx=rxlnxKdtdx=rxK+axK−xdtdx=rx(1−(Kx)θ)dtdx=(re1−(Kx)−d)x
自洽系统
对一阶常微分方程 x′(t)=f(x),若 f(x) 不显含变量 t,则称该方程为自洽系统(autonomous system)。
满足 f(x∞)=0 的 x∞ 称为平衡点(equilibrium point)。
对一阶常微分方程 x′(t)=f(x) ,或者 x(t) 无界,或者 t→∞limx(t)=x∞。但不是所有平衡点均为某个非零解的极限
可用线性化(linearization)方法研究平衡点附近解的性态
随机模型
记 x(t) 为 t 时刻一种群个体数量
-
x(t) 是一个取非负整数值的随机变量,{x(t),t≥0}为一随机过程
-
x(t)为连续时间齐次 Markov 链
- P{x(t+s)=j∣x(s)=i,x(u)=xu,0≤u<s}=P{x(t+s)=j∣x(s)=i}
- P{x(t+s)=j∣x(s)=i}值与 s 无关,记其为 pij(t)
-
设 x(t)=n , 种群在(t,t+Δt) 时段内
- 出生 1 人的概率为 λnΔt+o(Δt)
- 死亡 1 人的概率为 μnΔt+o(Δt)
- 出生和死亡事件总发生两次或以上的概率很小,忽略不计
生灭过程
生灭过程
离散状态空间连续时间齐次Markov链称为生灭过程(birth-death process),若对充分小的 Δt ,
pi,j表示在Δt时间内,从状态 i 转移到状态 j 的概率
⎩⎨⎧pi,i+1(Δt)=λiΔt+o(Δt),λi≥0,i≥0pi,i−1(Δt)=μiΔt+o(Δt),μi≥0,i≥1pi,i(Δt)=1−(λi+μi)Δt+o(Δt)⇒∣j−i∣≥2∑pij(Δt)=o(Δt)
- 纯生过程 (pure birth process) : μi=0,i≥0
- 纯灭过程 (pure death process) : λi=0,i≥0
- Poisson过程: μi=0,i≥0 , λi=λ,i≥0
家族消亡问题
- 分支过程(branching process)是用于描述与某一群体繁殖和转换相关的现象的随机过程,其基本假定是个体的繁殖是相互独立的
- 分支过程可用于描述传染病从极少感染者经过逐级传播到爆发的过程
- Fisher和Haldane曾用分支过程研究基因变异后的形成的不利基因通过自然选择在后代中的保留问题
"问题背景"
设每位家族成员之多有 k 个后代,有 i 个后代的概率为 pi,什么情况下家族会消亡?
假设:

我们有

记 xn 为家族在第 n 代的成员数。假设 x0=1(此时显然有 0≤xn≤kn )。
记 pj,n=P{xn=j},为家族到了第 n 代,后代个数为 j 的概率。定义 fn(x)=j=0∑knpj,nxj。记 pj,1=pj, f1(x)=f(x)
显然:
- 若xn−1=s,其中第 i 位成员的后代数为 ji∈[0,k],i=1,2,⋯,s,则有 xn=i=1∑sji,
- 所以 pj,n=s=0∑kn−1(ps,n−1⋅i=1∑sji=j∑(pj1pj2⋯pjs)),其中 ji∈[0,k],i=1,2,⋯,s。
将上式代入 fn(x) 的定义式,得到
fn(x)=j=0∑knpj,nxj=j=0∑knxjs=0∑kn−1ps,n−1i=1∑sji=j∑pj1pj2...pjs=s=0∑kn−1ps,n−1j=0∑kni=1∑sji=j∑xjpj1pj2...pjs=s=0∑kn−1ps,n−1(j1=0∑kj2=0∑k⋯js=0∑kxi=1∑sjipj1pj2...pjs)=s=0∑kn−1ps,n−1(j1=0∑kxj1pj1)(j2=0∑kxj2pj2)⋯(js=0∑kxjspjs)=s=0∑kn−1ps,n−1f1(x)s=fn−1(f1(x))
所以
fn(x)=fn−1(f1(x))=fn−2(f1(f1(x)))=⋯=f(f(⋯f(x)⋯))
fn(x) 是 f(x) 的 n 次复合函数。
例子
现在有一个家族,第一代有零个后代的概率为四分之一,有一个后代的概率为二分之一,有两个后代的概率为四分之一。(后代期望为1)
f(x)=41+21x+41x2
f(x)=f2(x)=f3(x)=41+21x+41x26425+165x+327x2+163x3+641x4163847921+2048445x+4096723x2+2048159x3+8192267x4+204819x5+409611x6+20481x7+163841x8
不断迭代下去,我们可以得到
f1(0)=0.250,f2(0)=0.391,f3(0)=0.483f4(0)=0.550,f5(0)=0.601,f6(0)=0.641
可见,没有后代的概率会越来越大,家族最终会消亡。
同样,对于 f(x)=81+21x+41x2+81x3,我们可以得到
f1(0)=0.125,f2(0)=0.192,f3(0)=0.231f4(0)=0.255,f5(0)=0.271,f6(0)=0.281
期望
第 n 代后代数的期望为
E(xn)=j=0∑knjpj,n=fn′(1)
根据复合函数的性质
fn′(x)=fn−1′(f1(x))f1′(x)
所以
E(xn)=fn′(1)=fn−1′(f1(1))f1′(1)=fn−1′(1)f1′(1)=⋯=f1′(1)n
消亡概率
记 πn 为第 n 代家族消亡的概率,即 πn=P{xn=0}
πn=p0,n=fn(0)=f(fn−1(0))=f(πn−1)
如果家族在第 n−1 代消亡,那么第 n 代也一定消亡,所以 πn−1≤πn,又 πn≤1,所以 {πn} 单调递增有上界,故 n→∞limπn 存在,记为 π∞。
π∞ 是方程 x=f(x) 的最小正根。
"证明"
-
π∞ 是方程 x=f(x) 的根
由于 πn=f(πn−1),所以 π∞=f(π∞),即 π∞ 是方程 x=f(x) 的根。
-
π∞ 是方程 x=f(x) 的最小正根
设另有一个正根 π∗,由于 f(x) 的单调性,有 π1=f(0)<f(x0)=x0,所以 π2=f(π1)<f(x0)=x0,所以 π3=f(π2)<f(x0)=x0,以此类推,可得 πn<x0。由极限的保号性, π∞≤x0。
可以证明,最终消亡概率 π∞=1 当且仅当 f′(1)≤1。
"证明"

由此,我们知道了家族在什么情况下会消亡。
16 传染病模型
传染病的基本概念
传染病得以在某一人群中发生和传播,必须具备传染源、传播途径和易感人群三个基本环节
基本模型
SIR模型
假设疾病传播期内所考察地区总人数保持不变,没有新增人口和因疾病以外的原因造成的死亡。
我们将人群分为三类:
- 易感者(Susceptible):未得病者,但缺乏免疫力,与感染者接触后会被感染
- 感染者(Infectious):已经感染病原体的人,可以传播疾病
- 移出者(Removed):不会再感染疾病,也不会再传播疾病,可能是因为死亡或者获得了免疫力或者被隔离
记 t 时刻易感者、感染者、移出者的人数分别为 S(t)、I(t)、R(t)
接触和移出
- 接触率:记为 β,表示单位时间内一个感染者与易感者接触的人数
- 移出率:记为 α,表示单位时间内一个感染者被移出的人数
单位时间内每人与 βN 个人接触,其中 N 为总人数,易感者占比为 NS(t),所以单位时间内一个感染者接触的易感者人数为 βNNS(t)=βS(t),单位时间内新增感染者数量为 βS(t)I(t)。
单位时间内移出感染者数量为 αI(t)
此时每个感染者处于感染期的时间服从参数为 α 的指数分布,那么单位时间内移出感染者数量为 αI(t),我们有
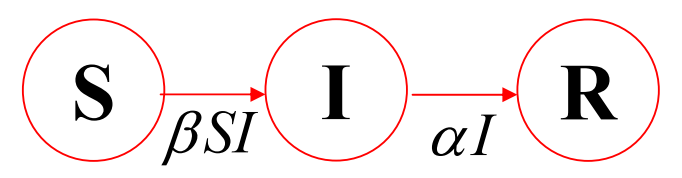
- P(X≤t)=1−e−αt,E(X)=α1
- 感染者经过长度至多为 t 的感染期后被移出的概率为 P(X≤t)=1−e−αt
- 若不计新增感染者,I(0)I(t)=e−αt
- 若不计新增感染者,dtdI(t)=−αI(t)
所以我们可以得到微分方程组
⎩⎨⎧dtdS=−βSIdtdI=βSI−αIdtdR=αI
其中,β 和 α 为常数,S(0)=S0,I(0)=I0,R(0)=R0,S0+I0+R0=N
我们考察 S 和 I 的关系,有
dSdI=−βSβS−α=βαS1−1≜σS1−1
其中,σ=αβ
可以解得
I(t)=S0+I0−S(t)+σ1lnS0S(t)
我们可以得到如下图像:
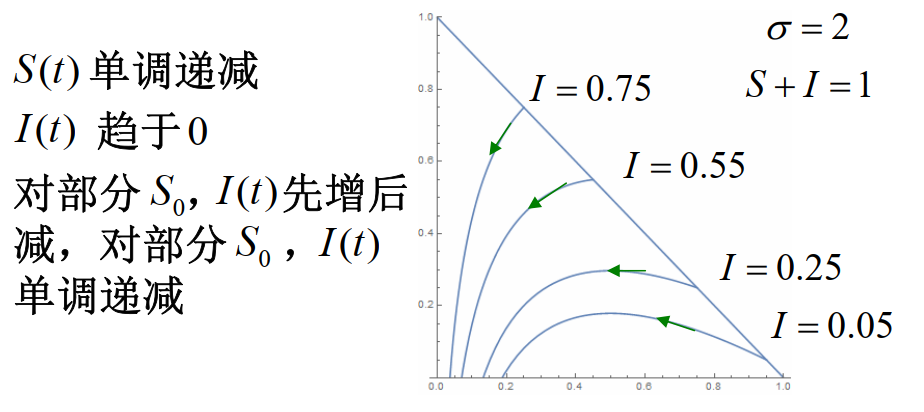
其中,横坐标为 S,纵坐标为 I。斜线上的点为 S0 和 I0,是初始点。上图所述的先增后减,实际上可以理解为疫情的爆发和衰退。
I 总会衰减到0吗?
因为 S(t)≥0,dtdS≤0,所以 S(t) 单调递减有下界,t→∞limS(t)存在,记为 S∞。
因为 R(t)≤N,dtdR≥0,所以 R(t) 单调递增有上界,t→∞limR(t)存在,记为 R∞。
因为 I(t)=N−S(t)−R(t),所以 t→∞limI(t)=N−S∞−R∞=I∞存在。
若 I∞=ϵ>0 ,则对充分大的 t,dtdR=αI(t)≥αϵ,所以 R(t)≥αϵt,t→∞limR(t)=∞,矛盾。
所以 I∞=0,即 I(t) 会衰减到0。
但是,I(t) 会衰减到0,不代表一定是好事,可能是因为所有人都痊愈了,也可能是因为所有人都寄了。
估计 σ
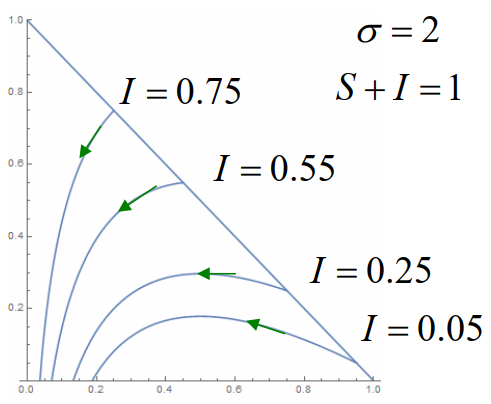
由该图可知,S∞ 即为 S0+I0−S(t)+σ1lnS0S(t)=0 的根
我们可以用 σ≈S0−S∞lnS0−lnS∞ 来估计 σ。
I(t) 的增减性
⎩⎨⎧dtdS=−βSIdtdI=β(S−σ)IdtdR=αI
若 S0>σ1
- σ1<S(t)<S0,dtdI>0,I(t) 单调递增
- S(t)=σ1,dtdI=0,I(t) 达到最大值 S0+I0−σ1(1+lnσS0)
- S(t)<σ1,dtdI<0,I(t) 单调递减至0
若 S0≤σ1,I(t) 单调递减至0,传染病不会爆发。
基本再生数
将上述增减性的分析应用过来,记 R0=S0σ,则前文分析情况就对应 R0>1 和 R0≤1。
R0=S0σ=S0αβ=α1⋅βN⋅NS0
- α1:每个感染者感染时间的期望值
- βN:单位时间内一个感染者接触的人数
- NS0:易感者占总人数的比例
所以这个式子表示每个感染者在感染期内感染的易感者平均数。
我们称 R0 为基本再生数。
SIS模型
假设疾病传播期内所考察地区总人数保持不变,没有新增人口和因疾病以外的原因造成的死亡。
我们将人群分为两类:
- 易感者(Susceptible):未得病者,但缺乏免疫力,与感染者接触后会被感染
- 感染者(Infectious):已经感染病原体的人,可以传播疾病
假设单位时间内每人与 βN 个人接触,并使其中的易感者受到感染。单位时间内 γI(t) 个感染者被治愈,重新成为易感者。
其中,β 和 γ 为常数,S(0)=S0,I(0)=I0,S0+I0=N
我们给出微分方程组
{dtdS=−βSI+γIdtdI=βSI−γI
所以
dtdI=β(N−I)I−γI=(βN−γ−βI)I=(βN−γ)I(1−βN−γβI)
感觉是不是和 Logistic 模型很像?
"Logistic 模型"
dtdx=rx(1−Kx)
- 若 βN−γ>0,∀I0∈(0,N),I(t) 单调递增趋向于 N−βγ
- 若 βN−γ<0,∀I0∈(0,N),I(t) 单调递减趋向于 0
记 R0=γβN,即当 R0>1 时,I(t) 单调递增趋向于 N−βγ,当 R0<1 时,I(t) 单调递减趋向于 0。
平衡点
自治系统有两个可能平衡点 P1=(N,0) 和 P2=(βγ,N−βγ)
- 当 R0>1 时,(S(t),I(t)) 趋向于 P1,人群中不再有感染者
- 当 R0<1 时,(S(t),I(t)) 趋向于 P2,传染病成为地方性疾病
防控传染病对策
- 减少人群接触,减小 β 值
- 提高治疗水平,使感染者尽早治愈,即增大 γ值
- 在存在移出者 (SIR) 情况下,通过预防免疫办法提高初始移出者 R0 至 N−βα
"为什么是 N−βα"
因为 dtdI=(βS−α)I,所以我们让未被感染的人群 S<βα,这样就可以让 dtdI<0,即 I 单调递减,疾病不会爆发。
Ross疟疾传播模型
疟疾只会在人类和蚊子,或者蚊子和蚊子之间传播,我们做出如下假设:
- 某区域在一段时间内人的数量 H 与(雌性)蚊子的数量 V 保持不变
- 记 t 时刻人群中易感者和感染者数量分别为 Sh(t) 和 Ih(t),蚊子中易感者和感染者数量分别为 Sv(t) 和 Iv(t)
- 单位时间内每只蚊子会叮咬 a 个(不同的)人,每个人被 a~ 只(不同的)蚊子叮咬,aV=a~H
- 发生叮咬时,从已感染疟疾的人传染给未感染疟疾的蚊子的概率为 bh,从已感染疟疾的蚊子传染给未感染疟疾的人的概率为 bv
- 单位时间内,有数量为 γhIh(t) 的已感染疟疾的人康复,数量为 γvIv(t) 的已感染疟疾的蚊子康复
通过分析,我们可以得到下图:
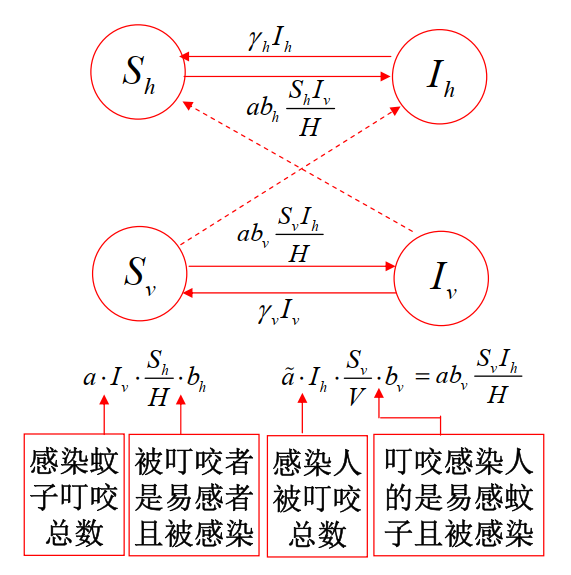
可以得到微分方程组
⎩⎨⎧dtdSh=−abhHShIv+γhIhdtdIh=abhHShIv−γhIhdtdSv=−abvHSvIh+γvIvdtdIv=abvHSvIh−γvIv
记
x(t)y(t)m=HIh(t)=1−HSh(t)=VIv(t)=1−VSv(t)=HV
则有
⎩⎨⎧dtdx=abh(1−x)my−γhxdtdy=abvx(1−y)−γvy
平衡点
令 dtdx=dtdy=0,则可以解得平衡点
(0,0),(abv(ambh+γh)a2mbhbv−γhγv,ambh(abv+γv)a2mbhbv−γhγv)
因为分子决定了平衡点的存在性,我们定义
R0=γhγva2mbhbv=γhabv⋅γhambh
- 当 R0>1 时,平衡点 (0,0) 不稳定,平衡点 (abv(ambh+γh)a2mbhbv−γhγv,ambh(abv+γv)a2mbhbv−γhγv) 稳定,疟疾会爆发
17 种间关系
"问题背景"
我们知道,生物种群之间存在着相互作用关系,比如食饵与捕食者之间的关系,竞争关系等等。那么,两个种群之间的相互作用关系该如何描述?
Lotka-Volterra 模型
记 x(t),y(t) 分别为 t 时刻食用鱼 (食饵) 和鲨鱼(捕食者)的种群数量。
假设海洋资源丰富,且:
- 食用鱼独立生存时以常数增长率增长;
- 而由于鲨鱼存在,使得食用鱼增长率减少,减少的程度与鲨鱼数量呈正比;
- 鲨鱼缺乏食用鱼时死亡率为常数;
- 食用鱼的存在使鲨鱼死亡率降低,降低的程度与食饵数量呈正比
我们可以列出如下的微分方程:
{dtdx=(r−ay)xdtdy=(−d+bx)y
其中,r,a,d,b 为正常数,分别表示食用鱼的原生增长率、鲨鱼捕食食用鱼的能力、鲨鱼死亡率、食用鱼对鲨鱼死亡的抑制能力。
所以,我们可以得到:
dxdy=(r−ay)x(−d+bx)y
这是一个分式微分方程,我们可以通过分离变量的方法求解:
dxdyyr−aydy∫(yr−a)dyrlny−ay(xde−bx)(yre−ay)=(r−ay)x(−d+bx)y=x−d+bxdx=∫(x−d+b)dx=−dlnx+bx+c=C
-
若 x(0)=x0,y(0)=y0, 则 C=(x0de−bx0)(y0re−ay0)
-
令f(x)=xde−bx,f(x) 在 xm=bd 处取得极大值fmax;令g(y)=yre−ay,g(y) 在ym=ar 处取得极大值 gmax
-
0≤C=f(x)g(y)≤fmaxgmax,若C=fmaxgmax,则 x=xm,y=ym, 相轨线退化为点 (xm,ym)
给定一些参数,我们可以画出相轨线:
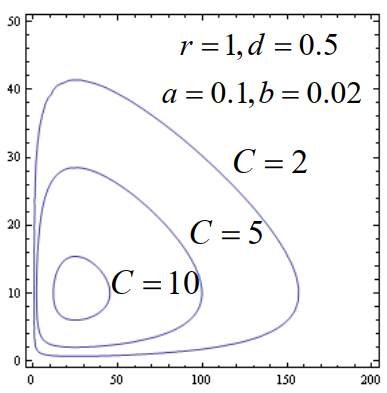
这是 C<fmaxgmax 的情况。
"为什么相轨线是一个圈?"
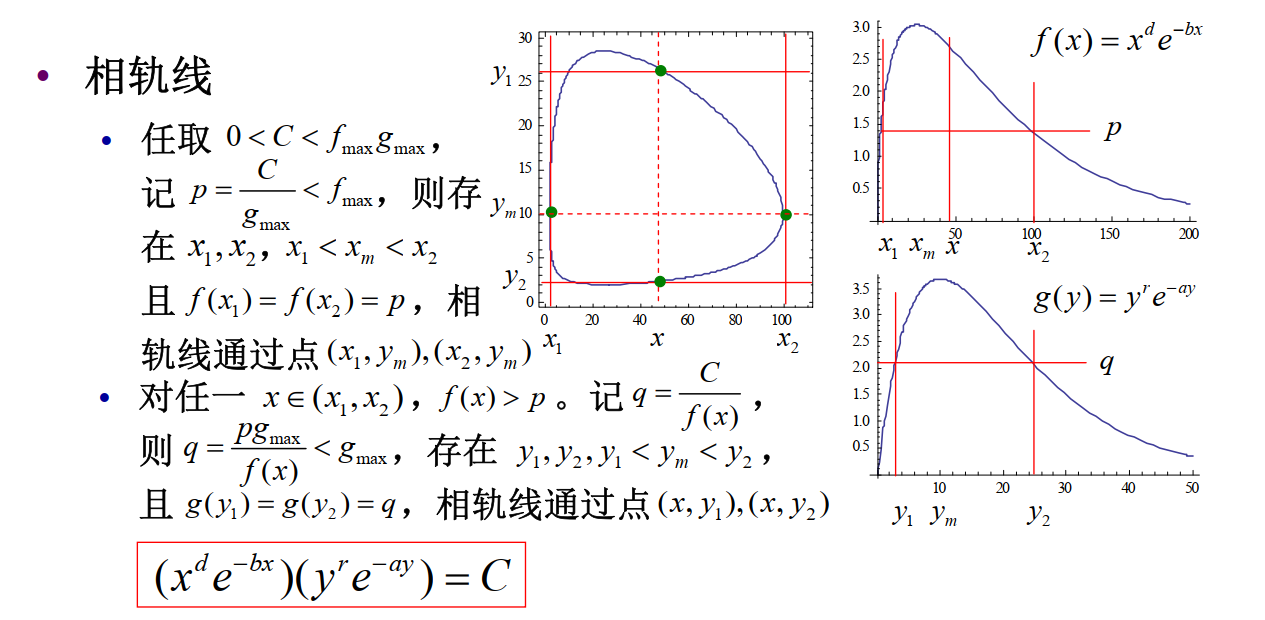
我们可以通过分析相轨线来分析种群的数量变化:
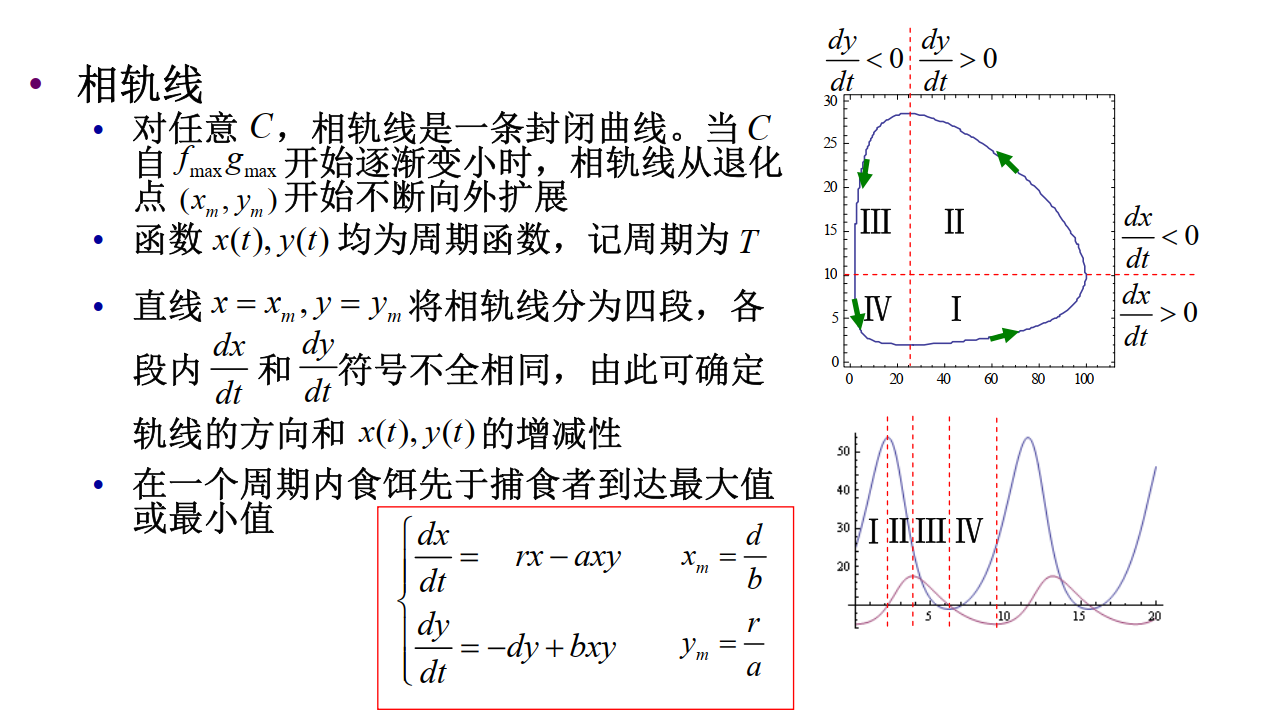

一般双种群模型
一般双种群模型的微分方程为:
{dtdx=x(a10+a11x+a12y)dtdy=y(a20+a21x+a22y)
-
记种群 X,Y 的增长率为 a10,a20
- a10>0 表示 X 可依靠系统外食物为生
- a20<0 表示 Y 必须依赖 X 为食才能生存
-
记种群 X,Y 的密度制约项为 a11,a22
- a11=0 表示X是非密度制约的
- a11<0 表示 X是密度制约的
-
种间关系
- 利用 (Exploitation) : a12<0,a21>0
- X为食饵,Y为捕食者,X为寄主,Y 为寄生物
- 种间竞争 (Interspecific competition) : a12<0,a21<0
- 共生 (Mutualism) : a12>0,a21>0
18 数学规划
运筹学
运筹学的主要分支:
- 数学规划(Mathematical Programming)
- 线性规划(Linear Programming)
- 非线性规划(Nonlinear Programming)
- 整数规划(Integer Programming)
- 多目标规划(Multiobjective Programming)
- 组合优化(Combinatorial Optimization)
- 随机运筹
- 排队论(Queuing Theory)
- 库存论(Inventory theory)
- 可靠性理论(Reliability Theory)
- 博弈论(Game Theory)与决策理论(Decision Theory)
数学规划
- 若干个变量在满足一些等式或不等式限制条件下,使目标函数取得最大值或最小值
- 研究问题的数学性质,构造求解问题的方法,实现求解问题的算法,以及将算法应用于实际问题
"数学规划分类"
"按函数性质"
- 线性规划(linear programming)
- 非线性规划(nonlinear programming)
- 目标函数为非线性函数,或至少有一个约束条件为非线性等式或不等式
- 二次规划(Quadratic Programming, QP):目标函数为二次函数,约束条件为线性等式或不等式
- 带二次约束的二次规划(Quadratically Constrained Quadratic Program, QCQP):目标函数为二次函数,约束条件为线性或二次等式或不等式
- 线性分式规划(linear fractional programming):目标函数为两个线性函数的商,约束条件为线性等式或不等式
"按变量性质"
整数规划(integer programming):至少有一个决策变量限定取整数值
- 整数决策变量意义
- 用于表示只能取离散值的对象的数量
- 用于表示约束条件之间的逻辑关系或复杂的函数形式
- 用于表示非数值的优化或可行性问题
- 特殊整数规划
- 部分决策变量取整数值的数学规划特称为混合整数规划(Mixed Integer Programming, MIP)
- 0-1规划:决策变量仅取值0或1的数学规划
数学规划建模的基本要求
- 数学规划模型是问题要求和限制的真实反映
- 数学规划模型的最优解(可行解)与问题最优解(可行解)是否一致或对应
- 是否遗漏问题的隐含约束、决策变量的必然要求、多组决策变量间的联系等约束条件
- 数学规划模型应符合数学规划的内容规范和形式要求
- 要素完整、变量指标运用准确。逻辑关系、集合运算等一般不在数学规划中出现
- 问题可能存在多个数学规划描述,需根据实际情况进行选择和不断完善
- 复杂目标函数和约束条件的简化, 0-1变量的灵活运用
- 可行域约简、数学规划的重构、分解与松弛
数学规划建模的适用范围
- 具有简单最优算法或可转化为已知多项式时间可解问题,不需运用数学规划求解
- 最优解不具必要性,或求解时间要求高于精度要求等问题,不宜盲目运用数学规划求解
- 建立数学规划模型困难,因实例规模或问题结构等原因使求解不具现实可能性的问题,不能直接运用数学规划求解
食谱问题

也就是说,我们要找到在约束条件下的 x,使得到 mini=1∑ncixi。(大概是多元线性规划?)
例如:
mins.t.60x1+30x2+20x3120x1+180x2+160x3≥50300x1+90x2+30x3≥90x1,x2,x3≥0
运输问题

数独
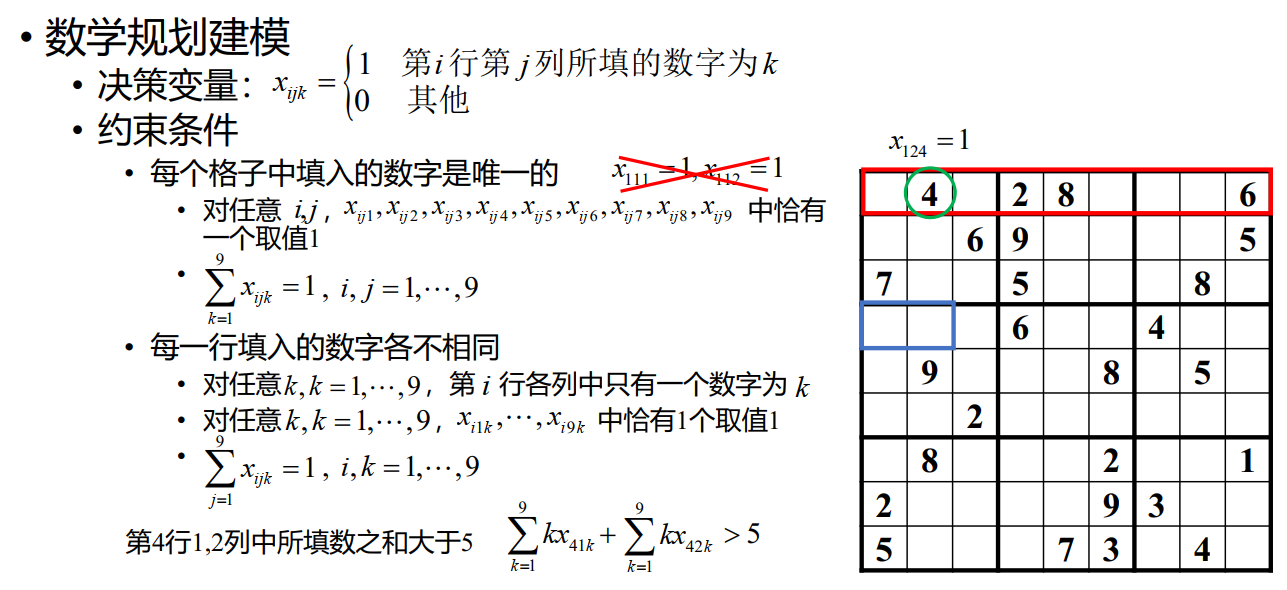
k=1∑9kxijk 的值为在这个格子里填的数字。

下料问题
"问题背景"
现有 W 米长的钢管若干。生产某产品需长为 wi 米的短管 bi 根,i=1,2,⋯,n。如何截取能使材料最省?
我们构造数学规划模型:
决策变量:xji 表示第 j 根钢管截取第 i 种短管的数量,i=1,2,⋯,k,j=1,2,⋯,n。(n=i=1∑kbi)
约束条件:
- 每根钢管截取的短管总长度不超过钢管长度 W,即 i=1∑nwixji≤W,j=1,2,⋯,n
- 每种短管截取的数量不低于需求量,即 j=1∑nxji≥bi,i=1,2,⋯,k
我们的目标是使得截取的钢管最少,即 minn。但这个 n 是出现在求和号上的,在线代的数学规划中我们往往不会直接去求解这个 n,而是将其转化。
我们构造一个 0-1变量 yj,表示第 j 根钢管是否被截取,即 yj=1 表示第 j 根钢管被截取,yj=0 表示第 j 根钢管未被截取,j=1,2,⋯,n。
所以我们的目标函数可以写成 minj=1∑nyj。
但现在有一个问题:yj 与 xji 之间的关系是什么呢?
∃i,xji>0→yj=1⇒i=1∑kxji>0→yj=1
约束条件1可以写成 i=1∑kwixji≤Wyj,j=1,2,⋯,n。
所以我们有:
mins.t.j=1∑nyji=1∑kwixji≤Wyjj=1∑nxji≥bixji≥0,yj∈{0,1}
当 yj=1→∃i,xji>0。给定目标下,最优解自动满足。
另一种决策变量
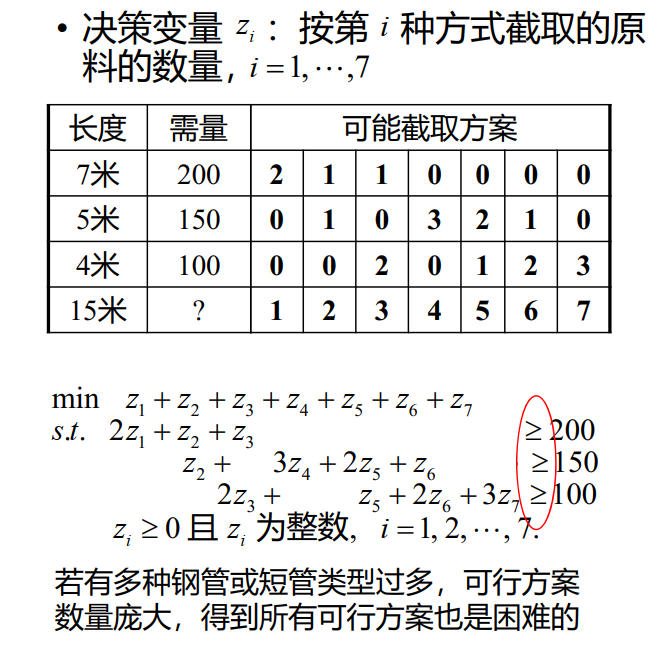
同样,这个解法可以用于解决装箱问题。
装箱问题
两个问题实际上是同一个问题,只是描述的方式不同。
装箱问题指的是给定一系列大小已知的物品和若干个容量相同的箱子,如何将物品放入箱子中,使所用箱子数尽可能少。
三维的情况往往不使用数学规划,而是使用启发式算法。
选址问题
"问题背景"
平面上有 n 个点,求一个面积最小的圆,使得这 n 个点都在圆内。
记第 j 个点的坐标为 (xj,yj),j=1,2,⋯,n。我们给出一个带二次约束的二次规划模型:
决策变量:圆心坐标 (x0,y0),圆半径 r
目标函数:minr2
约束条件:(xj−x0)2+(yj−y0)2≤r2,j=1,2,⋯,n
约束为二次时,比较难写,我们可以将其转化成更简单的形式:
决策变量改为 λ=r2−(x02+y02)
目标函数改为 minλ+(x02+y02)
约束条件改为 λ+2x0xj+2y0yj≥xj2+yj2,j=1,2,⋯,n
时间分配问题
"问题背景"
有 T 天时间可用于安排复习 n 门课程,每天只能复习一门课程,每门课程至少复习一天。用 t 天时间复习第 j 门课程可使该门课程提高 pjt 分。如何制定复习计划可使所有课程提高的总分尽可能大?
决策变量:xjt 表示第 j 门课程是否复习 t 天,j=1,2,⋯,n,t=1,2,⋯,T
xjt={1,0,第 j 门课程复习 t 天其他
目标函数:maxj=1∑nt=1∑Tpjtxjt
约束条件:t=1∑Txjt=1;j=1∑nt=1∑Ttxjt≤T
19 赛程编制
- Symmetry and separation(对称性和分离性)
- Breaks(出现连续的客场或主场比赛--这是我们不愿看到的)
- The carry-over effect
图的因子分解
图 G 的因子分解,指将 G 分解为若干边不重的因子之并——因子指至少包含G的一条边的生成子图。
一个图G的 n 因子,是指图G的 n 度正则因子——正则因子指所有顶点的度数都是 n 的因子。
一个 K−8 完全图的 1 - 因子分解如下(不同颜色的边表示不同的因子):
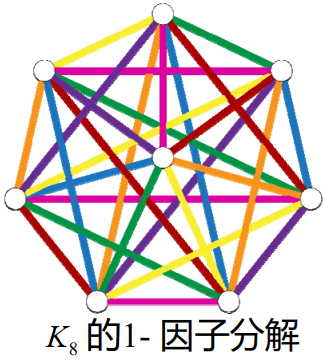
根据因子分解,我们可以给出赛程编制的一种方法:
同时,我们也可以根据因子分解,给出主客场的安排(尽量不安排连续的客场或主场比赛),例如第一轮和第二轮中:
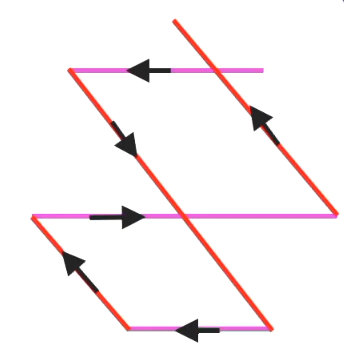
根据这条路的开头和结尾,我们给出了主客场的安排。
但我们的第八支队伍还没有安排,但无论怎么安排,都会出现breaks:
这时排出来 6 种break,而这已经是最少的break了,接下来我们给出一般情况下至少有的break数。
breaks数
对 n(偶数)支队伍的赛程,用形如 HAH…HA,长度为 n−1(奇数)的字符串表示每支队伍的主客场安排,称为模式(pattern)
"单循环赛程"
n 支队伍的单循环赛程,全程所有队伍总break数至少为 n−2
因为任意两支队伍的模式是互不相同,而只有HAHA…HAH 和 AHAH…AHA 两种模式没有break,其它模式的break数至少为 1,所以总break数至少为 n−2
"镜像双循环赛程"
n 支队伍的镜像双循环赛程,全程所有队伍总break数至少为 3n−6
- 若半程没有break,则全程也没有break,这样的队伍至多有两支(HAHAH-AHAHA,AHAHA-HAHAH)
- 若半程有且仅有一个break,由于模式字符串长度为奇数,在前后半程之间有一个break(H A A H A - A H H A H),break数为 3
- 若半程有至少两个break,全程break数至少为 4
所以总break数至少为 3(n−2)
"n(偶数)支队的镜像赛程中的double-round break"
此时赛程分成多个阶段,我们只考虑每个阶段中的 double-round break。
因为队伍为偶数支,所以每支队伍的模式字符串长度为奇数。
- 若半程没有break,则全程也没有break,这样的队伍至多有两支(HAHAH-AHAHA,AHAHA-HAHAH)
- 若半程至少有1个break,全程至少有2个double-round break(H A | A H |A - A | H H | A H),根据奇数长度的模式字符串,我们可以得到:
- 前后半程之间若有break,必为double-round
- 若前半程的break不为double-round,后半程的break必为double-round
所以总double-round break数至少为 2(n−2)
"其他方案"
法制的 break 数可以到 0 ,最终我们采用法制。
数学规划
我们来到实际问题:有 10 支队伍,每阶段两场比赛
决策变量:xijk={1,0,第k轮第i支队伍在主场对阵第j支队伍其他
"例子"
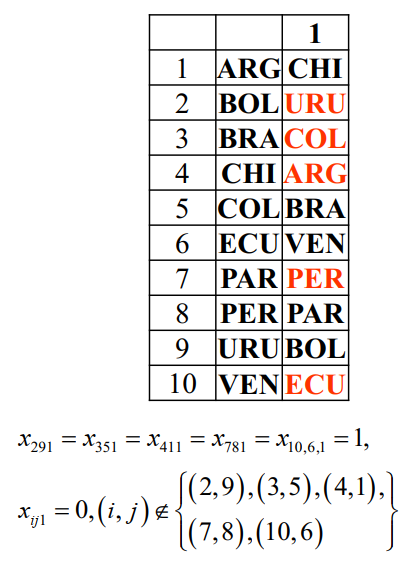
约束条件(部分):
- 每轮各队恰有一场比赛:i=1∑10(xijk+xjik)=1,j=1,2,⋯,10,k=1,2,⋯,18
- 任意两队在前后半程各交手一次:k=1∑18xijk=1,i,j=1,2,⋯,10,i=j
- 任意两队之间的两场比赛中每队均有一个主场:k=1∑9(xijk+xjik)=1,k=9∑18(xijk+xjik)=1,i,j=1,2,⋯,10,i=j
- 任一队不连续与种子队(用 Is 表示)对阵:j∈Is∑(xijk+xjik+xi,j,k+1+xj,i,k+1)≤1, i∈I∖Is,k=1,⋯,18
均衡各阶段主场次数
每支队伍各阶段先主后客(先客后主)的次数尽可能均衡:
定义辅助变量 yil={1,0,第l阶段第i支队伍先主后客第l阶段第i支队伍先客后主
xijk 与 yil 之间的关系:
yil=1⇔j=1∑10xi,j,2l−1=1且j=1∑10xj,i,2l=1
改写一下就是:
⎩⎨⎧j=1∑10(xi,j,2l−1+xj,i,2l)≤1+yilyil≤j=1∑10xi,j,2l−1yil≤j=1∑10xj,i,2l
每支队伍先主后客的总次数尽可能均衡时,4≤l=1∑9yil≤5,i=1,2,⋯,10
各阶段连续客场的次数尽可能少
在法制双循环赛制中 xi,j,1=xj,i,18, xi,j,k=xj,i,k+8, k=2,3,⋯,9,i,j=1,2,⋯,10,i=j
定义辅助变量 wil={1,0,第l阶段第i支队伍两场比赛均为客场其他,i=1,2,⋯,10,l=1,2,⋯,9
xi,j,k 与 wil 之间的关系:
wil=1⇔j=1∑10xj,i,2l−1=1且j=1∑10xj,i,2l=1
改写一下就是:
⎩⎨⎧j=1∑10(xj,i,2l−1+xj,i,2l)≤1+wilwil≤j=1∑10xj,i,2l−1wil≤j=1∑10xj,i,2l
目标函数 为:mini=1∑10l=1∑9wil
最后的结果为:
20 支持向量机
"问题背景"
将一数据集 S 分为 C1,C2 两类,每个数据有 n 个特征。我们应该如何通过训练集来找出一个超平面,使得它判别效果最好?
问题描述
我们拟将一数据集 S 分为 C1,C2 两类。每个数据有 n 个特征,用 n 维实向量表示,我们有训练集 S′={x1,⋯,xm},其中 xi∈Rn,记 yi={1,xi∈C1−1,xi∈C2。
假设训练集可线性分离,即存在超平面 w⋅x+b=0,使得对于所有 i,有 yi(w⋅xi+b)>0。
"超平面"
设 w 为 n 维实向量,b 为实数,w⋅x+b=0 称为 Rn 中的超平面。
- Rn 中的点 x 到超平面 w⋅x+b=0 的距离为 ∥w∥∣w⋅x+b∣。
- 若 w⋅w=1,则距离为 ∣w⋅x+b∣。
我们现在要做的是找到一个超平面,使得它到两类数据的距离最大(判别效果最好)。
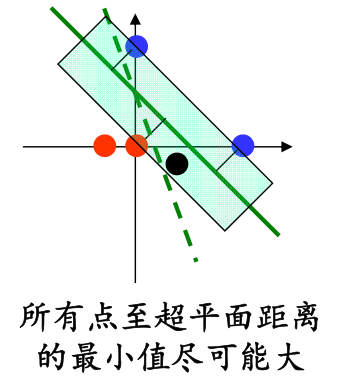
数学规划
根据上面的描述,我们可以得到如下的数学规划问题:
s.t.maxi=1,⋯,mmin∣w⋅xi+b∣yi(w⋅xi+b)≥0,i=1,⋯,m∥w∥=1
本目标含绝对值与极小值,约束含二次函数,极难计算。我们将绝对值去掉,得到如下的数学规划问题:
s.t.maxi=1,⋯,mminyi(w⋅xi+b)∥w∥=1
"证明可以转换"

但此时目标含极小值,约束含二次函数,依旧难以计算。我们将极小值去掉,得到如下的数学规划问题:
s.t.min∥w∥yi(w⋅xi+b)≥1
"证明可以转换"

21 数学规划求解
线性规划
矩阵形式
s.t.mincxAx=bx≥0
不妨设系数矩阵 A=(aij)m×n 为行满秩矩阵,即 rank(A)=m
- 若 rank(A)<m ,则存在冗余约束
不妨设 A 的前 m 列线性无关
- 重排 A 的列,并相应调整决策变量的顺序
标准型
- 目标函数极小化
- 决策变量取非负值
- xj 无限制 ⇔xj=xj+−xj−,xj+,xj−≥0
- 所有约束均为等式约束
- Ax≤b⇔Ax+y=b,y≥0
- Ax≥b⇔Ax−y=b,y≥0
- 等式约束右端均为非负常数
最优解的类型
线性规划有四种最优解的类型:唯一最优解、无穷多最优解、无可行解、无界解(有可行解,但最优值无下界)。
基与基可行解

线性规划基本定理
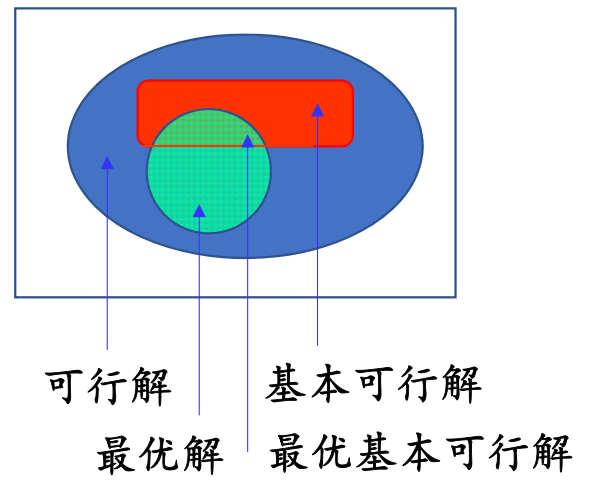
- 若线性规划有可行解,必有基本可行解
- 若线性规划有最优解,必有最优基本可行解
求解算法
单纯形法
从一个基本可行解转到另一个基本可行解,并使目标值下降。迭代有限次,找到最优解或判断最优值无界
单纯形法是指数时间算法。存在含 m 个变量 m 个约束的线性规划,单纯形法需要进行 2m−1 次迭代
实践表明,对多数线性规划问题,单纯形法迭代次数为变量和约束数的多项式函数
多项式时间算法
1979年,Khachiyan给出了求解线性规划的第一个多项式时间算法 —— 椭球算法。
1984年,Karmarkar给出了实际效果更好的多项式时间算法——内点法,产生了深远的影响
整数线性规划

分枝定界法
分枝定界法 是求解整数规划最常用的算法,算法思想可用于其它离散优化问题的求解。它是一种指数时间算法。
分枝定界法的基本思想
- 用线性规划求解松弛问题,得到松弛问题的最优解
- 若最优解为整数解,则该整数解为整数规划的最优解
- 若最优解不是整数解,则将松弛问题的可行域分为两个子可行域,分别求解这两个子问题
- 重复上述过程,直到找到整数解或判断无整数解
"例子"
IP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1,x2≥0,x1,x2∈Z
我们先求解松弛问题:
LP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1,x2≥0
画图易得,松弛问题的最优解为 (x1,x2)=(49,415),目标函数值为 −202.5
由于最优解不是整数解,我们将松弛问题的可行域分为两个子可行域:
x1≥3,x1≤2
对于第一个子可行域,我们有:
IP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1≥3x1,x2≥0,x1,x2∈Z
LP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1≥3x1,x2≥0
画图易得,松弛问题的最优解为 (x1,x2)=(3,3),目标函数值为 −198。此时为整数解,停止迭代。
对于第二个子可行域,我们有:
IP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1≤2x1,x2≥0,x1,x2∈Z
LP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1≤2x1,x2≥0
画图易得,松弛问题的最优解为 (x1,x2)=(2,935),目标函数值为 −200,此时 x2 不是整数,我们将松弛问题的可行域分为两个子可行域:
x2≥4,x2≤3
对于第一个子可行域,我们有:
IP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1≤2x2≥4x1,x2≥0,x1,x2∈Z
LP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1≤2x2≥4x1,x2≥0
画图易得,松弛问题的最优解为 (x1,x2)=(95,4),目标函数值为 −198。此时不为整数解,但是继续做下去,函数值只会更大,所以停止迭代。
对于第二个子可行域,我们有:
IP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1≤2x2≤3x1,x2≥0,x1,x2∈Z
LP: min−30x1−36x2,s.t.⎩⎨⎧x1+x2≤65x1+9x2≤45x1≤2x2≤3x1,x2≥0
画图易得,松弛问题的最优解为 (x1,x2)=(2,3),目标函数值为 −168。此时为整数解,停止迭代。
所以,整数规划的最优解为 (x1,x2)=(3,3),目标函数值为 −198。
22 多目标规划
多目标规划的概念
多目标规划研究变量在满足给定约束条件下,多个可数值化的目标函数同时极小化的问题:
minf(x)=f1(x)f2(x)⋮fm(x),s.t.x∈S,S={x∣{gi(x)≤0,i=1,2,⋯,shj(x)=0,j=1,2,⋯,t}
多目标规划解的类型
绝对最优解 Sa:在所有可行解中,同时使所有目标函数取得最小值的解
- 对任意 x∈S ,有 fi(x∗)≥fi(x),i=1,2,⋯,p
Pareto最优解(有效解/非劣解)Sp:
- 不存在 x∈S ,使得所有 fi(x)≤fi(x∗),i=1,2,⋯,p ,且至少有一个 fi(x)<fi(x∗)(非严格不等号)
弱Pareto最优解 Swp:
- 不存在 x∈S ,使得所有 fi(x)<fi(x∗),i=1,2,⋯,p (非严格不等号)
解的关系
"Sa 与 Swp 之间的关系"
Sa 与 Swp 之间的关系(横坐标为 x,纵坐标红线为 f1,蓝线为 f2):
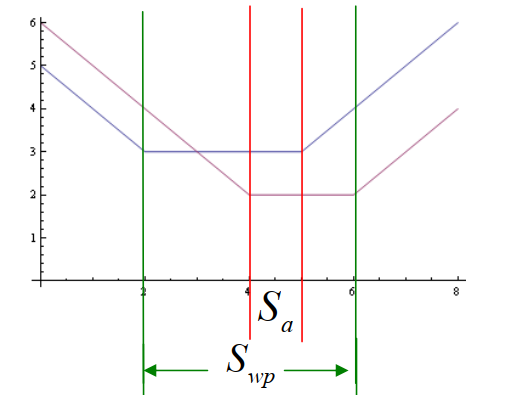
我们通常将其画为(纵坐标为 f1,横坐标为 f2):
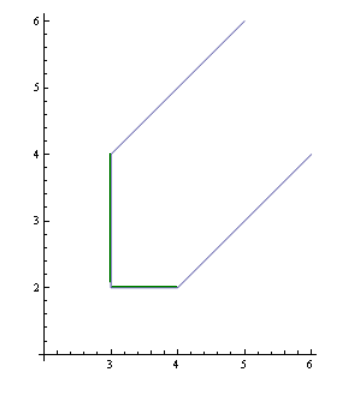
其中,左下角的交点为 Sa ,绿线为 Swp
"Swp 与 Sp 之间的关系"
Swp 与 Sp 之间的关系(横坐标为 x,纵坐标红线为 f1,蓝线为 f2):
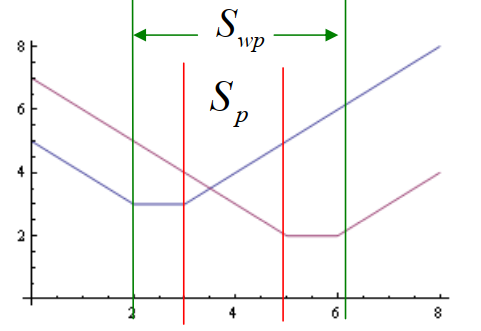
我们通常将其画为(纵坐标为 f1,横坐标为 f2):
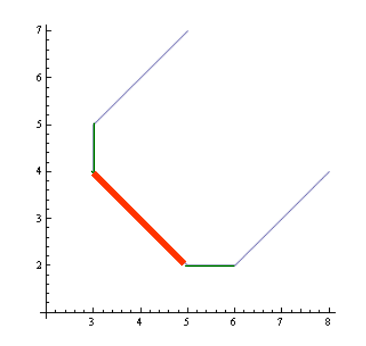
其中,红线为 Sp ,绿线为 Swp
可以证明 Sa⊆Swp⊆Sp⊆S
"证明"
-
若 x∗∈Sa,但 x∗∈/Sp,则存在 x∈S 和某个k,使得fk(x)<fk(x∗),fl(x)≤fl(x∗),l=k,与x∗∈Sa矛盾
-
若 x∗∈Sp,但 x∗∈/Swp,则存在 x∈S,使得fk(x)<fk(x∗),k=1,⋯,p,与 x∗∈Sp矛盾。
若 Sa=Swp ,则称 Sa 为Pareto最优解,此时 Sa=Swp=Sp
多目标规划的求解
线性加权和法

主要目标法

理想点法
对任意k,取fk0≤minz∈Sfk(x),λ∈Λ={λ∣λ≥0,k−1∑pλk=1},求解单目标规划 (Pi(α))x∈Smin(k=1∑pλk(fk(x)−fk0)α)α1
在实际情况下,我们可以将 λ 取为 1,α 取为 2
- 对任意 α≥1,Pλ(α) 的最优解为弱Pareto最优解
- 若λk≡p1,对任意 α≥1,Pλ(α) 的最优解为Pareto最优解
分层排序法

例子:投资组合

采用主要目标法

"简略版"

23 组合优化
组合优化的基本概念
组合优化是应用于离散对象的,从有限多个可行解中找出使某个目标函数达到最优的解的优化问题
- 组合优化是离散数学(Discrete Mathematics)与最优化的交叉学科分支
组合优化与连续优化
"连续优化"
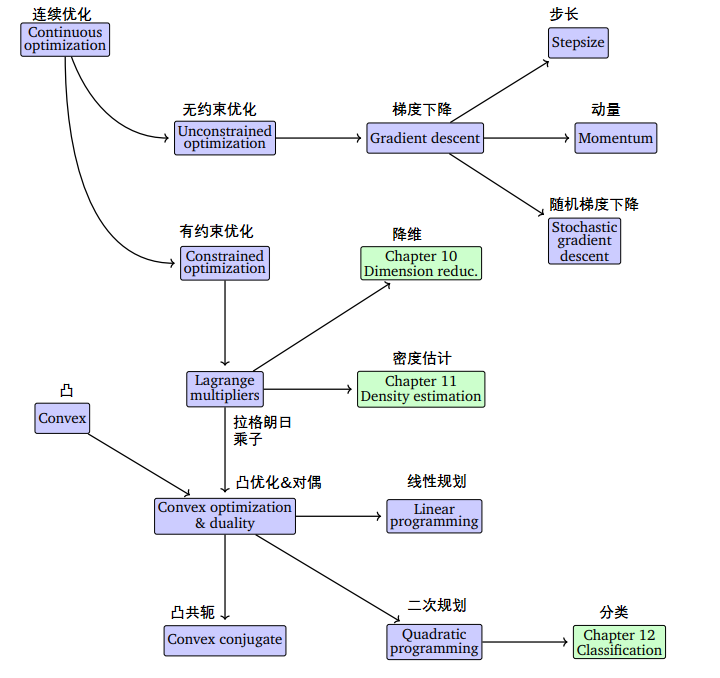
连续优化是应用于连续对象的,从无限多个可行解中找出使某个目标函数达到最优的解的优化问题
相对决策变量为连续变量的连续优化(Continuous Optimization)问题,组合优化问题的最优解缺少好的性质,求解缺少好的工具
组合优化例子
背包问题
连续背包问题
现有 n 件物品,物品 j 的价值为pj,大小为 wj。 物品质地均匀,可任意切割
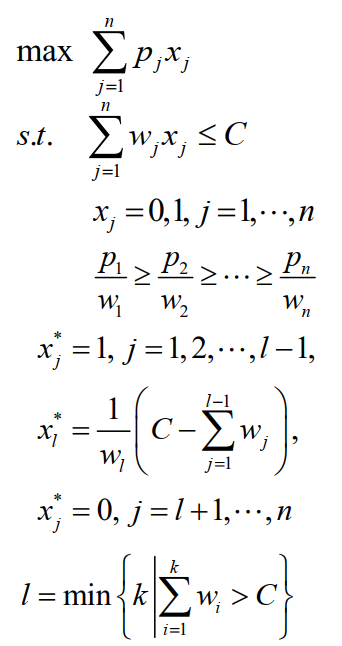
离散背包问题
现有 n 件物品,物品 j 的价值为pj,大小为 wj。 物品不可切割
旅行商问题 - TSP
旅行售货商问题(TravelingSalesman Problem, TSP)
- 一推销员想在若干个城市中推销自己的产品。计划从某个城市出发,经过每个城市恰好一次,最后回到出发的城市
- 城市之间距离已知
- 如何选择环游路线,使推销员走的路程最短
可行解(环游)
- 每一条环游路线由 n 段两个城市之间的旅行路线连接而成,对应于 1,2,⋯,n 的一个圆周排列
车辆路径问题 - VRP

指派问题

排序问题

算法与计算复杂性
Pv.s.NP 问题
P 和 NP 问题的通俗解释:
- P:有(确定性)多项式时间算法的问题
- NP:有非确定性多项式时间算法的问题
确定性算法是一种特殊的非确定性算法,故 P⊆NP
所谓 Pv.s.NP 问题是指 P=NP 还是 P⊂NP ?
- Pv.s.NP 问题是数学和计算机科学中的重大未解决难题之一
- 目前多数人相信 P⊂NP。此时背包问题等,不存在多项式时间内求得最优解的算法
NP - 完全性理论
NP – 完全与 NP – 难 的通俗解释:
- NP–C:NP 类中最难的问题
- 若一个 NP–C 问题有多项式时间算法,所有 NP 问题都有多项式时间算法
- NP–hard:不比 NP–C 问题容易的问题
- 在 P=NP 假设下, NP - 难 问题不存在多项式时间最优算法
NP–hard 可以是 NP 问题,也可以不是 NP 问题
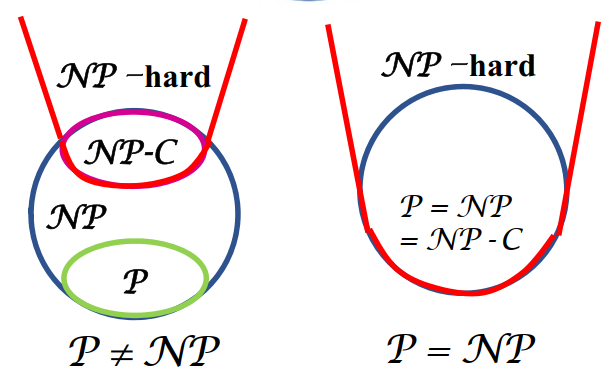
在 P=NP 假设下,多数组合优化问题分属 P 问题 和 NP–hard 问题
NP-完全问题举例
SAT 问题
SAT 问题(Satisfiability Problem)

图同构问题(目前还没完全证明)
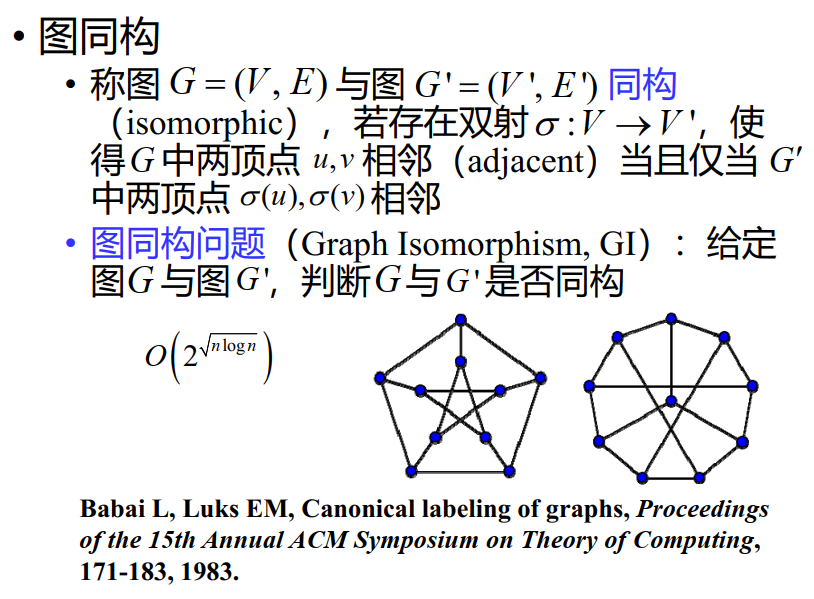
组合优化的求解
组合优化问题通常不能通过穷举所有可能的解加以比较来求解,因为可行解的数目可能是一很大的数,以致于当前或相当长的一段时间内人力或计算机不能承受
贪心算法
贪心算法:在每一次决策时,选择当前可行且最有利的决策
场馆安排问题
贪心算法:按结束时间从小到大的顺序排列最优

排序悖论
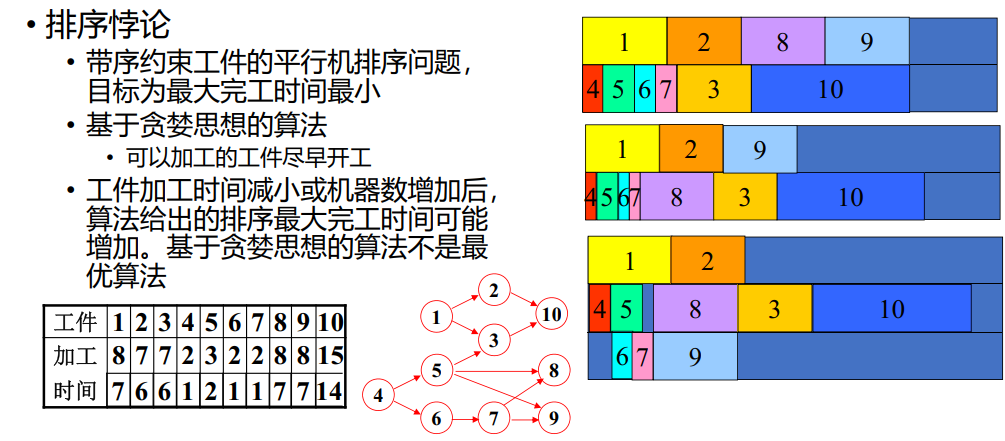
右边第二个是所有加工时间-1,第三个是增加一条线。可见,后面两个竟然不如前面的好,这就是贪婪思想的局限性
实际上,这个问题是 NP - 难问题,没有多项式时间算法
动态规划
动态规划是求解多阶段决策优化问题的一种数学方法和算法思想
背包问题的动态规划算法


麦子收集
一 n 行 m 列的棋盘,在棋盘的部分格子中各放有一颗麦子
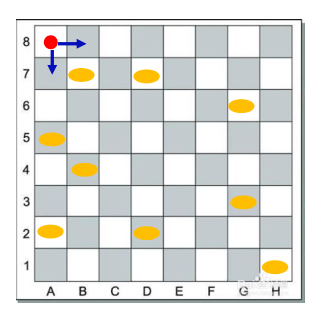
- 一机器人从棋盘左上角的格子出发收集麦子。机器人只能从当前所
在格子向下或向右移动一格,到达放有麦子的格子后,即能收集该
格子中的麦子
- 如何使机器人到达棋盘右下角的格子时,收集的麦子数量尽可能多
我们给出动态规划解法:

启发式算法
启发式算法(heuristic)是基于某种直观想法、合理假定,或者借助物理、化学、生命科学中的一些原理而设计的算法,体现了在求解的最优性、精确性与求解资源之间的权衡。启发式算法的有效性一般需通过计算机模拟验证。
- 遗传算法(genetic algorithm)
- 模拟退火算法(simulated annealing)
- 禁忌搜索(tabu search)
- 蚁群算法(ant colony optimization)
- 粒子群优化算法(partial swarm optimization)
元启发式算法
元启发式算法是一种高层次的问题无关的算法框架,它提供了一组指导方针或策略来开发启发式优化算法
近似算法
算法的时间复杂性可通过分析确定(一般要求多项式时间),且算法给出的近似解与最优解目标值之间的差距可通过证明来严格估计
装箱问题
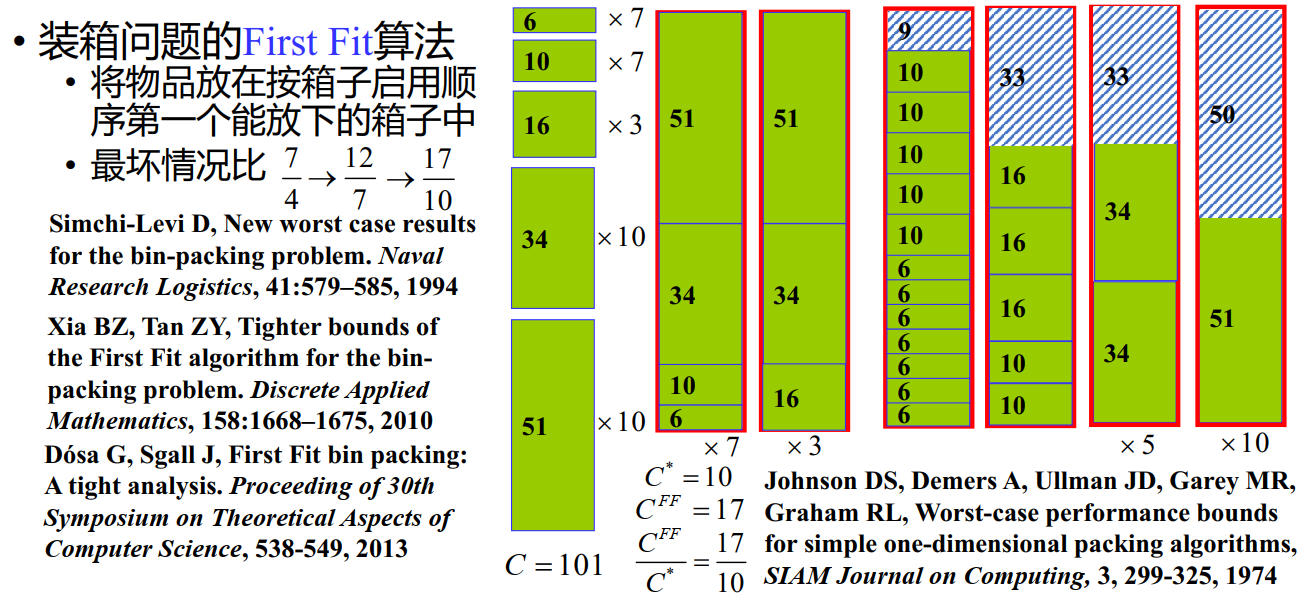
24 图论模型
图的基本概念
图
图是一个有序二元组 G=(V,E),其中 V 是顶点(vertex)集合,E 是边(edge)的集合。E 中每条边 e 与 V 中两个顶点关联(incident)。
- 若与边关联的两个顶点有序,则称图为有向图(digraph),否则称为无向图
度:无向图 G 中与顶点 v 关联的边的数目称为 v 的度,记为 d(v)(degG(v))
- 图的所有顶点的度的最大值与最小值分别称为最大度和最小度, 记为 Δ(G) 和 δ(G)
- (握手定理)所有顶点的度之和等于边数的两倍,即 ∑v∈Vd(v)=2∣E∣
简单图
两端点相同的边称为环(loop),两端点分别相同的多条边称为平行边(parallel edges)
既没有环,也没有平行边的图称为简单图(simple
graph)。不是简单图的图称为多重图(multigraph)
完全图
任何两个不同顶点之间都有边相连的简单图称为完全图(complete graph)
- n 个顶点的完全图记为 Kn, Kn的边数为 2n(n−1)
简单图的顶点数与边数
- 若 G=(V,E) 为简单图,则边数的上界为 2∣V∣(∣V∣−1),下界为 ∣V∣−1
- 边数接近上界的称为稠密图(dense graph),边数远离上界的称为稀疏图(sparse graph)
二部图与连通

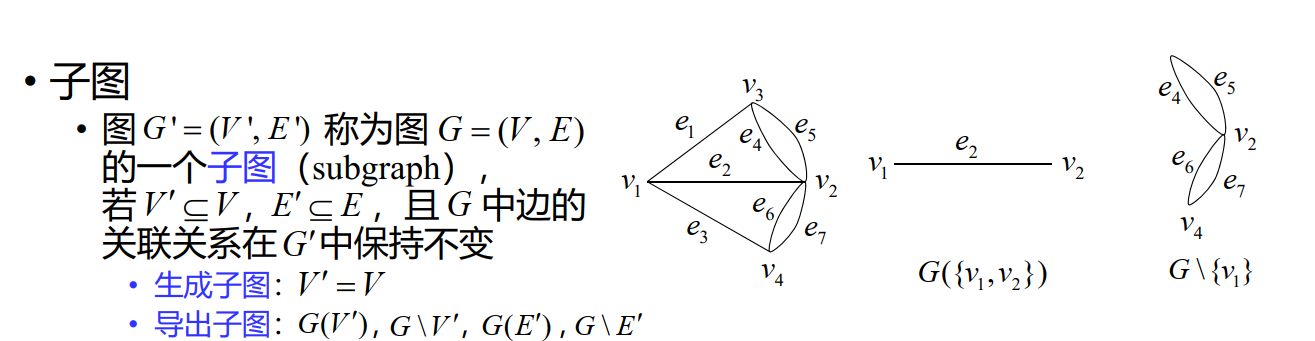
子图
路
顶点和边交替出现的序列 vi0ei1vi1ei2⋯eikvik,且序列中与每条边相邻的两个顶点为该边的两个端点,称为连接顶点 vi0 和 vik 的途径(walk)
经过边互不相同的途径称为迹(trail)
经过顶点互不相同的途径称为路(path)
- 起点和终点相同,其余顶点互不相同,也不与起点和终点相同的途径称为圈(cycle)
路的长度
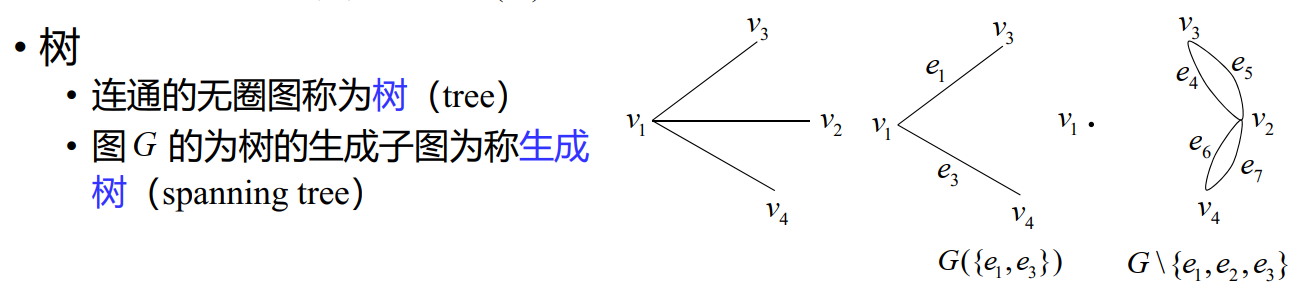
树
最小生成树
最小生成树(MST)是赋权图所有生成树中总权和最少的生成树
####### Kruskal 算法 {#kruskal-算法 }

最短路

最短连接
给定Euclidean平面上 n 个点,如何用总长度最短的若干条线段将它们连接起来?
用最小生成树解决最短连接问题:构造 n 个顶点的赋权完全图 Kn,边的权为它的两个端点的Euclidean距离。问题的解即为 Kn 的最小生成树
最小 Steiner 树
允许增加任意多个Steiner点的最短连接(就是说,可以在原有的点集中增加任意多个点,使得最后的连接线段总长度最短)
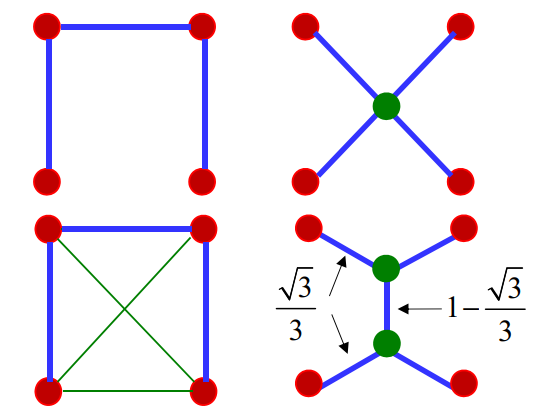
####### Gilbert-Pollak猜想 {#gilbert-pollak猜想 }
最小Steiner树长度不小于最小生成树长度的 23倍
n=3,4,5,6 时,猜想成立
Hamilton 圈 与 Hamilton 图
经过图的所有顶点恰好一次的圈称为 Hamilton圈(Hamiltion cycle)
存在Hamilton圈的图称为Hamilton图
Icosian game
一个正十二面体的二十个顶点各代表一个城市,是否有一条从某个城市出发,沿正十二面体的棱行走,经过每个城市恰好一次,最后回到出发城市的路线?
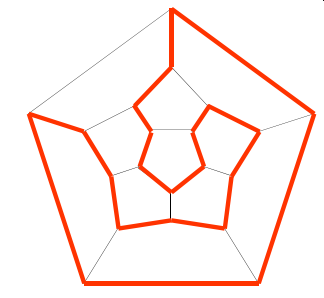
骑士环游 | Knight’s tour
在 8×8 国际象棋棋盘上,马能否按其走子规则,从一个格子出发,经过其它格子恰好一次,最后回到起点?
- 构造“跳马图”,每一格子为图的一个顶点,两个格子之间有
边相连当且仅当马可按走子规则从一个格子跳到另一个格子
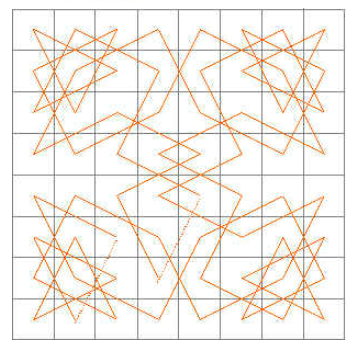
推广为 m×n 棋盘上的骑士环游问题

特殊顶点集
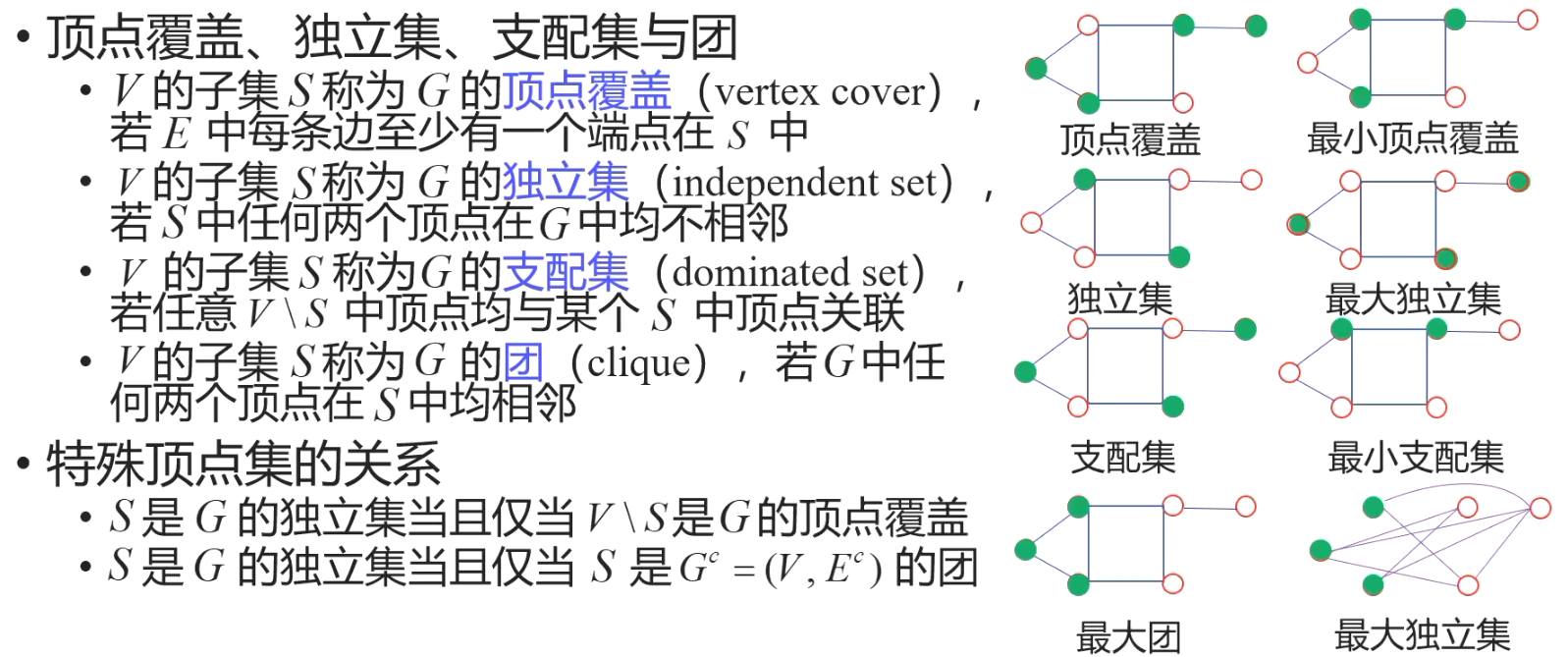
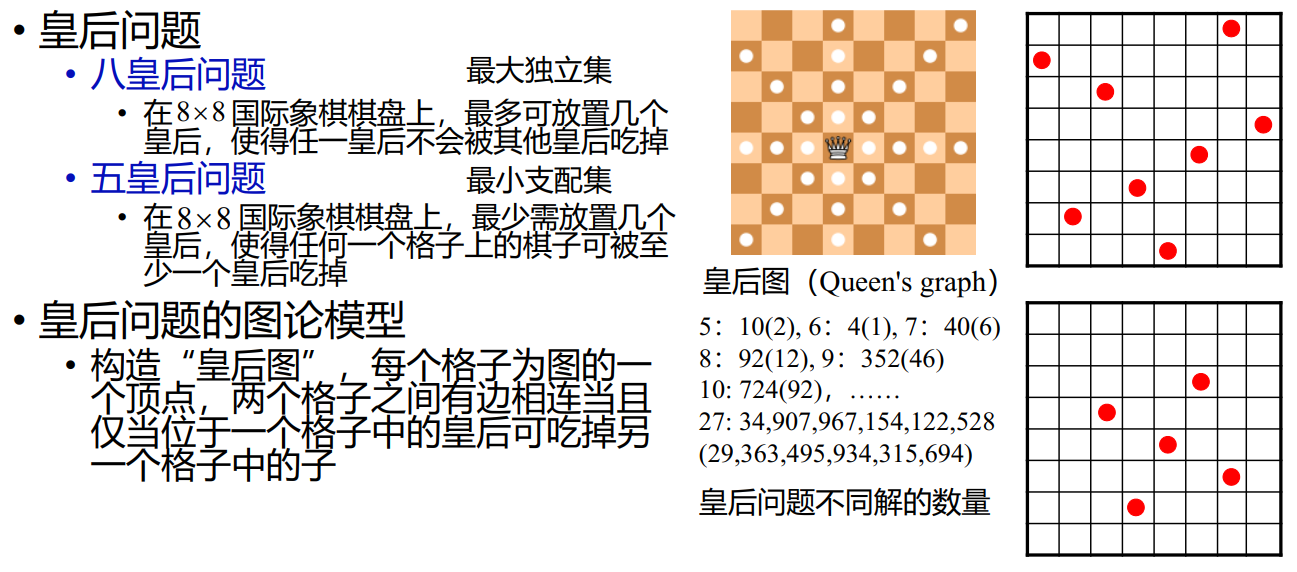
皇后问题
匹配(边集)

Hall 定理 与 Frobenius 定理


例如:
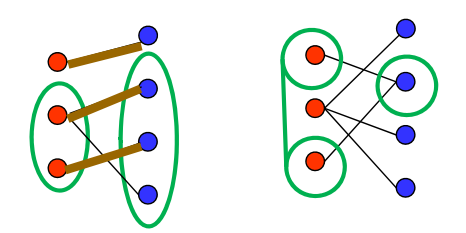
左图中,∣S∣=2≤3=∣N(S)∣
右图中,∣S∣=2≰1=∣N(S)∣
因为二者 左右顶点数不同,所以不能完美匹配
Hall定理的等价定理
图的问题
选址问题
"问题背景"
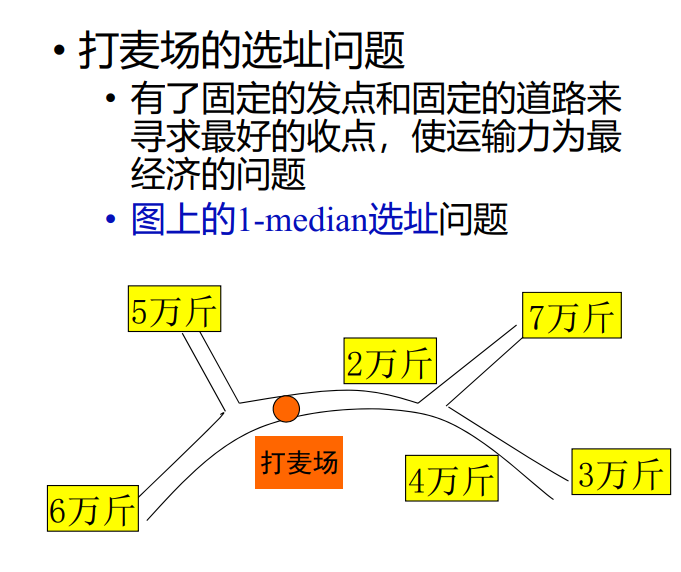
无回环情况
"第一步"
"第二步"

"例子"
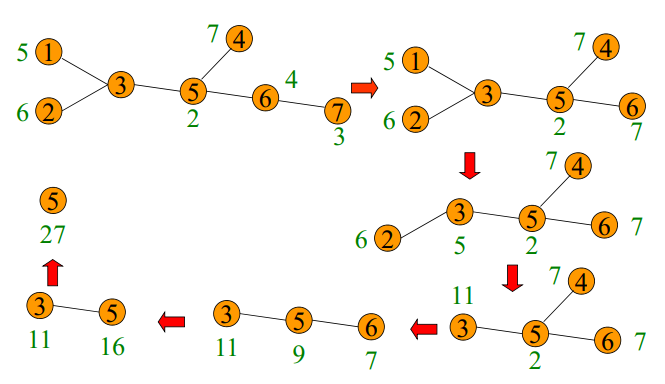
有回环情况
"口诀"
道路有回环,每圈甩一段,
化为无回环,然后照样算。
甩法有不同,结果一一算,
算后再比较,最优可立断。
例如:
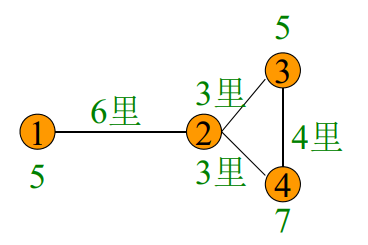
将圈甩为:
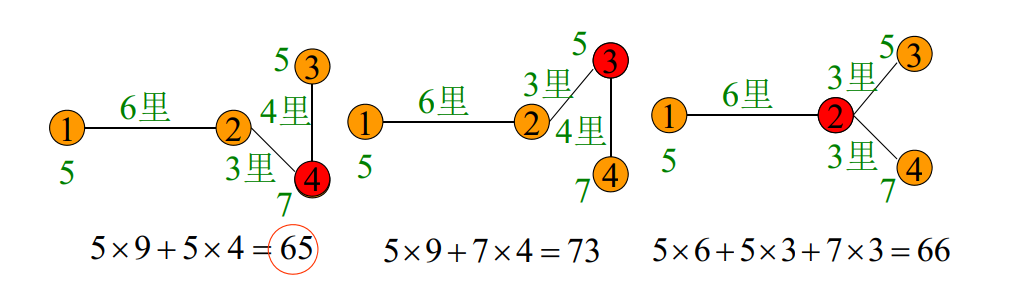
七桥问题
"问题背景"
在 Konigsberg 城,有七座桥梁建在 Pregel 河上,是否有一条从城中某处出发,经过每座桥梁恰好一次,最后回到出发点的路线?
Euler 图
经过图的所有边恰好一次的闭迹称为 Euler 回路(Eulerian circuit)。存在 Euler 回路的图为 Euler 图(Eulerian graph)。
一连通图是 Euler 图的充要条件是图中没有奇度顶点。
以河流分割而成的城市区域为顶点,桥梁为边,边的端点为该桥梁连接的两片区域。七桥问题等价于在该图中寻找一条闭迹。
可以证明,七桥问题无解。
中国邮递员问题(Chinese postman problem | CPP)
"问题背景"
一个投递员每次上班,要走遍他负责送信的段,然后回到邮局。问应该怎样走才能使所走的路程最短?
- 将邮递员走过的区域建模为赋权图。街道为边,街道交汇
处为顶点,边的权为街道的长度。
- 若赋权图是 Euler 图,任何一条 Euler 回路都是中国邮递员
问题的最优解。
- 若赋权图不是 Euler 图,寻找一条总长度最短的回路,该回
路可能经过某些边两次以上。
着色
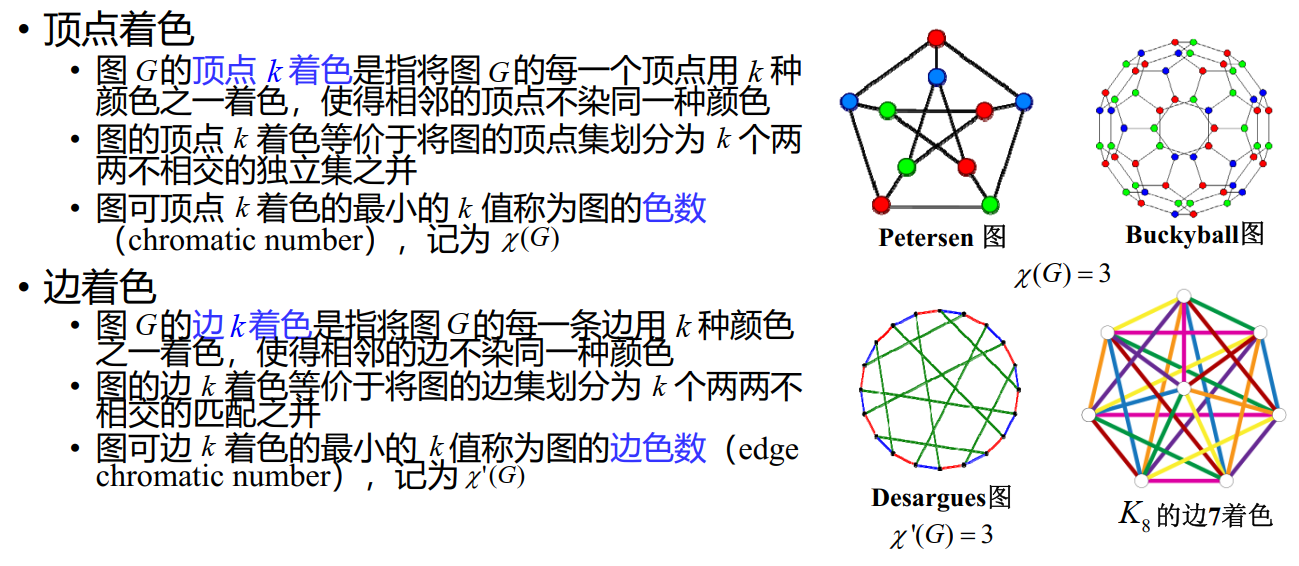
Ramsey 数
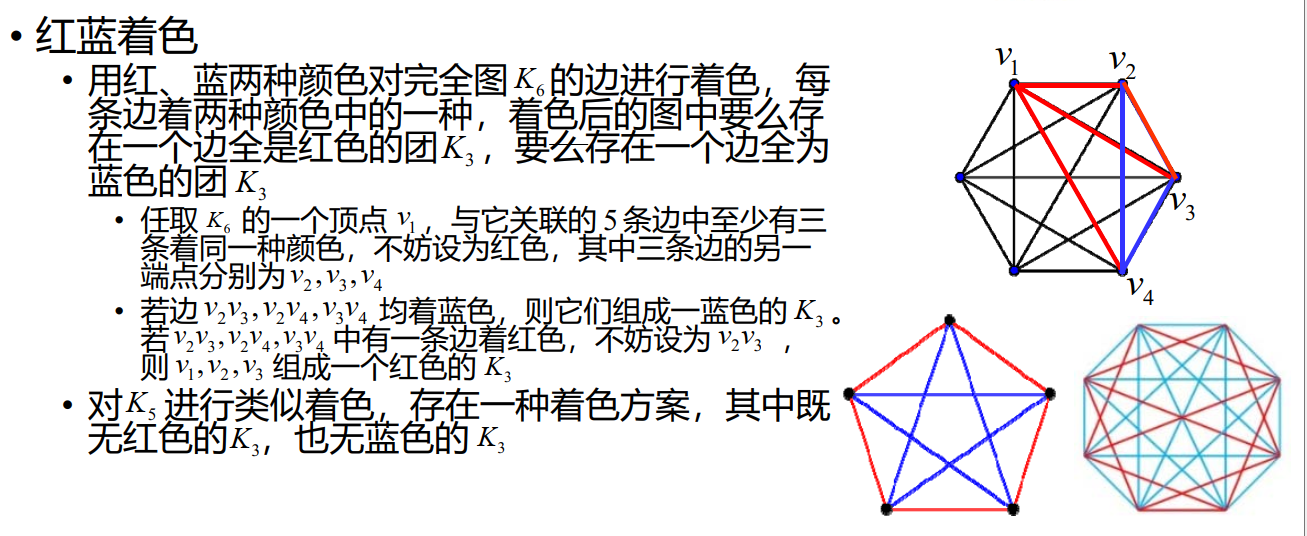

(IMO 1964) 17 位科学家中每一位和其余 16 位通信,在他们的通信中所讨论的仅有三个问题,而任两位科学家通信时所讨论的是同一问题,证明至少有三位科学家通信时所讨论的是同一问题。

推广 Ramsey 数到三维,在这题就是 R(3,3,3)=17
割

网络流


算法与复杂性
图的应用
搭档方法

获胜队伍
一个 2n 个队伍的循环赛持续了 2n−1 天,每天每个队伍都和另一个队伍比赛,每场比赛都有一个队伍获胜,一个队伍失败。在整个比赛中,每个队伍都和其他队伍比赛了一次。我们能不能在每天都选择一个获胜的队伍,而且每个队伍只能被选择一次?

黑白异位
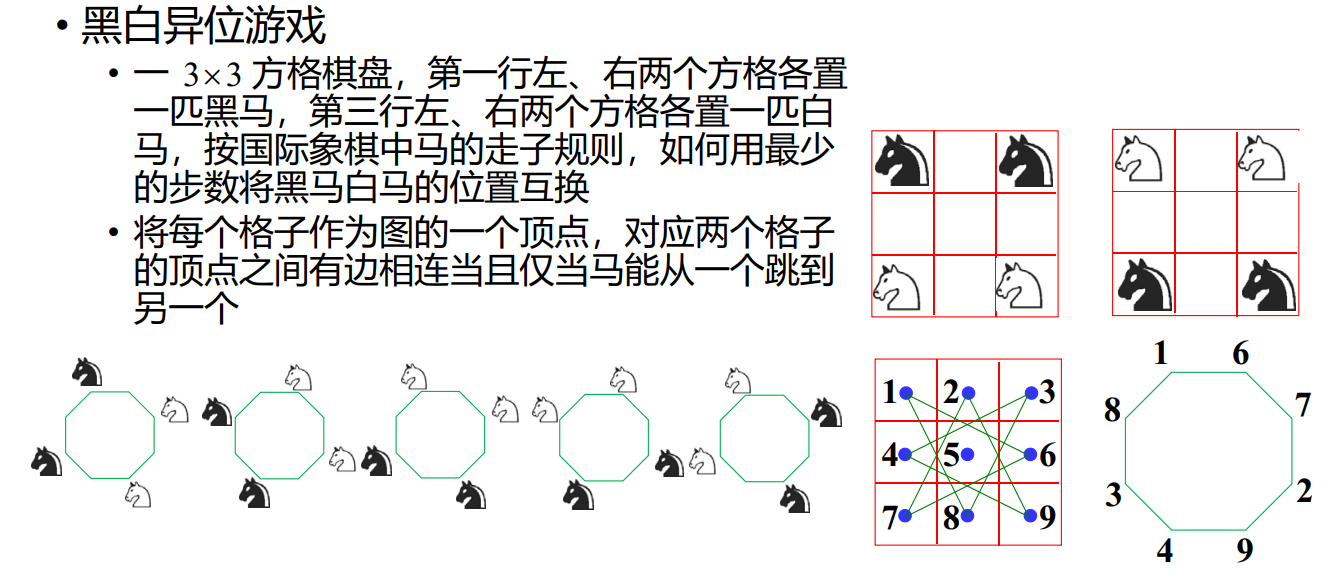
分水问题
现有A,B,C三个水瓶,其容积分别为12,8,5升。 A瓶装满水, B,C为空瓶。现欲利用B,C两瓶,将A瓶中的水均分,并使倾倒次数最少

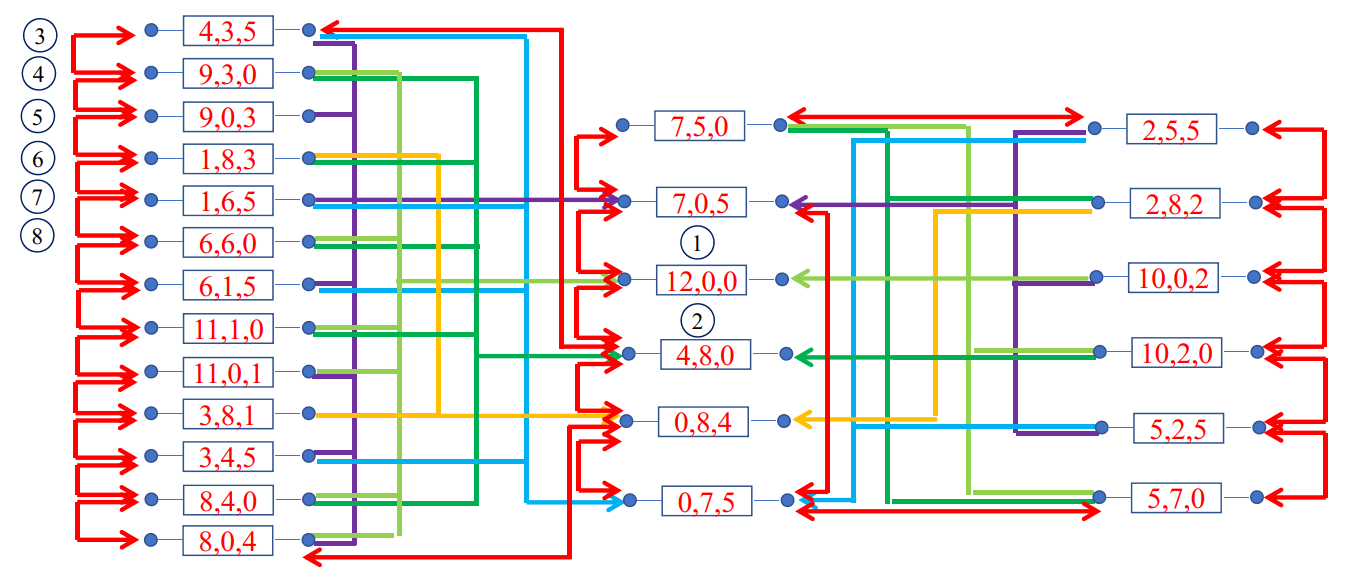
好像是列出了所有的情况,然后找到最短的路径。从中间的 (12,0,0) 到左边的 (6,6,0)
代表问题
某校共有 m 个专业,为调研 n 门课程的教学情况,邀请部分同学参加座谈
- 每门课程有一名同学参加
- 各门课程邀请的学生各不相同
- 来自专业 i 的学生数不超过 ai
可以用网络流解决
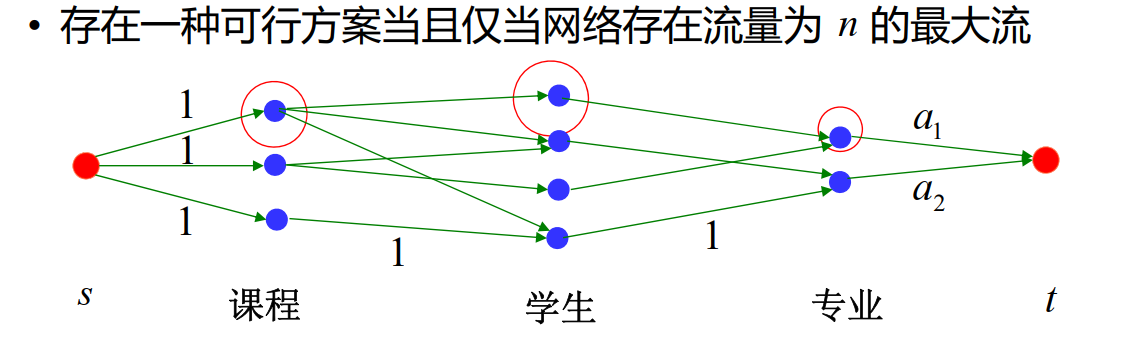
电缆与管道问题
中心配电房位于某幢建筑内,一些主干用户位于其
他不同的建筑内。为避免相互干扰,中心配电房与
每个主干用户需有一条专门的电缆相连
- 电缆需铺设在地下管道内,多条电缆可以共用一条
地下管道,有些建筑之间的道路可能不允许开挖管
道
- 铺设电缆的单位长度费用为 γ ,开挖管道的单位长
度费用为 τ
- 寻找一种方案,使总费用尽可能少
对电缆来说是最短路问题,对管道来说是最小生成树问题
未来网络 · 寻路

25 博弈论
博弈论的基本概念
博弈论研究由一些带有相互竞争性质的主体所构成的体系的理论。它能以数字表示人的行为或为人的行为建立模式,研究对抗局势中最优的对抗策略和稳定局势,以及如何追求各方的最优策略和决定对策的结果,协助人们在一定规则范围内寻求最合理的行为方式
博弈的要素
- 参与者(player):参与博弈的决策主体
- 策略(strategy):参与者可以采取的行动方案
- 策略组合(strategy profile):所有参与者选择的策略的集合
- 收益(payoff):参与者在某一策略组合下的收益
- 费用(cost):参与者在某一策略组合下需付出的代价
博弈论的假设
参与者是理性的,以最大化他的收益或最小化他的费用作为选择策略的准则
博弈的分类
合作博弈(cooperative game):局中人之间可以结成联盟,协调彼此的策略,并对获得的收益进行再分配
静态博弈(static game):所有参与者同时选择策略并行动,且只能行动一次,参与者选择策略时不知道其他参与者的选择。
完全信息(complete information):参与者掌握其他参与者的可选策略和收益等信息
完美信息(perfect information):在动态博弈中,参与者掌握其他参与者已选择的策略
简单例子
囚徒困境(Prisoner's Dilemma)
甲、乙两人共同犯罪,警方掌握了一部分犯罪事实,将他们带到警局分别讯问
- 若两人均承认所有罪行,则各被判处6个月徒刑
- 若一人认罪,一人不认罪,前者被轻判1个月徒刑,后者被重判9个月徒刑
- 若两人均不认罪,则以部分罪行各被判处2个月徒刑
|
乙认罪 |
乙不认罪 |
| 甲认罪 |
甲6个月,乙6个月 |
甲1个月,乙9个月 |
| 甲不认罪 |
甲9个月,乙1个月 |
甲2个月,乙2个月 |
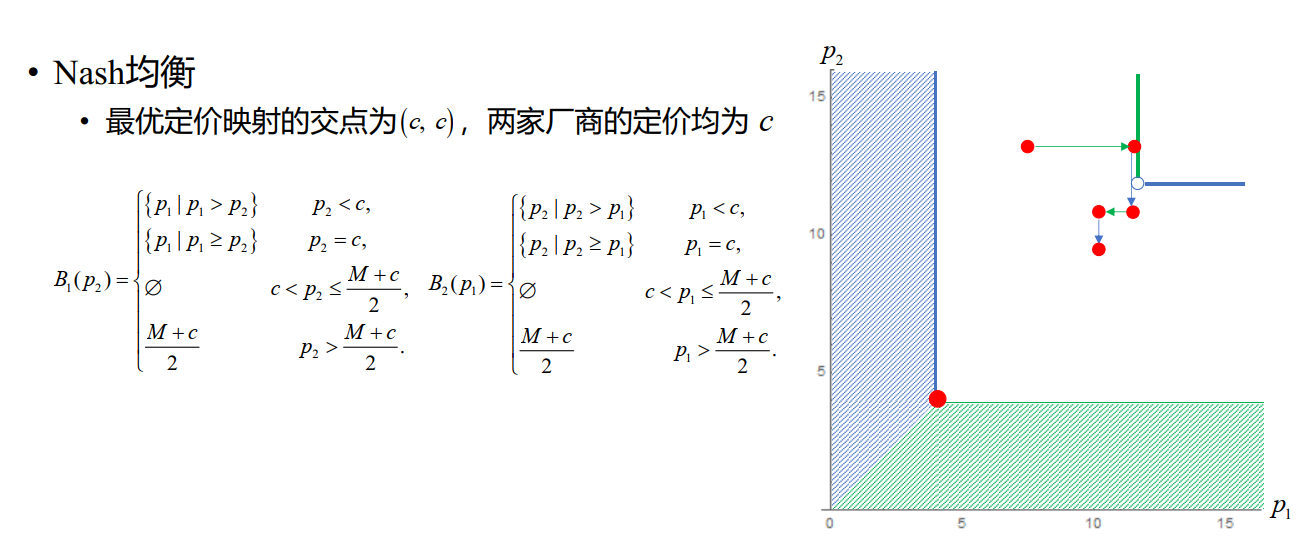
Nash 均衡
Nash 均衡(Nash equilibrium)
- (完全信息静态)博弈的某个局势,每一个理性的参与者都不会单独偏离它
- 对每一个参与者,在其他参与者策略不变情况下,单独采取其他策略,收益不会增加
纯策略与混合策略
纯策略(pure strategy):参与者每次行动都选择某个确定的策略
混合策略(mixed strategy):参与者可以以一定的概率分布选择若干个不同的策略
Nash 定理
若参与者有限,每位参与者的策略集均有限,收益函数均为实值函数,则博弈必存在混合策略意义下的 Nash 均衡
最优反应函数
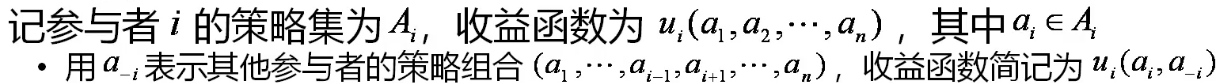
对其他参与者的任一策略组合,参与者的最优反应函数为可使其收益达到最大的策略集合,记为 Bi(a−i),即 Bi(a−i)={ai∗∣ui(ai∗,a−i)≥ui(ai∗,a−i),∀ai∈Ai}
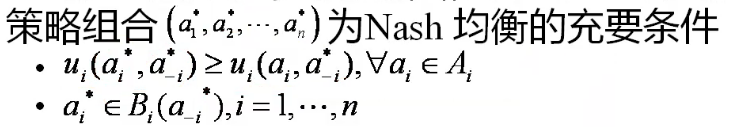
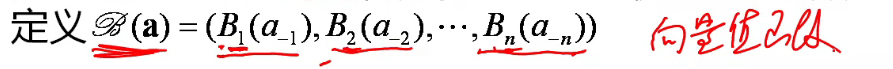
则充要条件可写为 a∗∈B(a∗)
如果只有一个的话,那就是 a∗=B(a∗),我们可以由此想到不动点定理
不动点定理

Nash 均衡的例子
Battle of Sexes
♂️:一起看球赛,收益为3;一起逛街,收益为1;各自行动,收益为0
♀️:一起看球赛,收益为1;一起逛街,收益为3;各自行动,收益为0
| (♂️,♀️) |
♂️ 看球赛 |
♂️ 逛街 |
| ♀️ 看球赛 |
(3,1) |
(0,0) |
| ♀️ 逛街 |
(0,0) |
(1,3) |
可见,双方看球或双方逛街都是均衡状态
鸽鹰博弈(Hawk-Dove Game)
| (A,B) |
B:鸽子 |
B:鹰 |
| A:鸽子 |
(0,0) |
(-1,1) |
| A:鹰 |
(1,-1) |
(-5,-5) |
可见,一方鹰,另一方鸽子是均衡状态
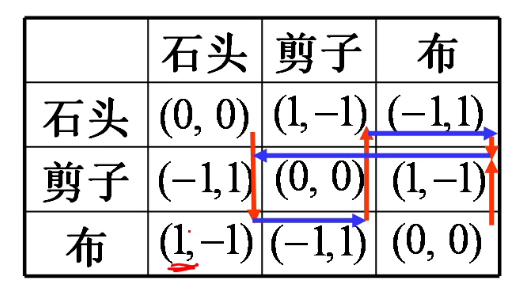
石头剪刀布
不存在 Nash 均衡
让座

Braess 悖论
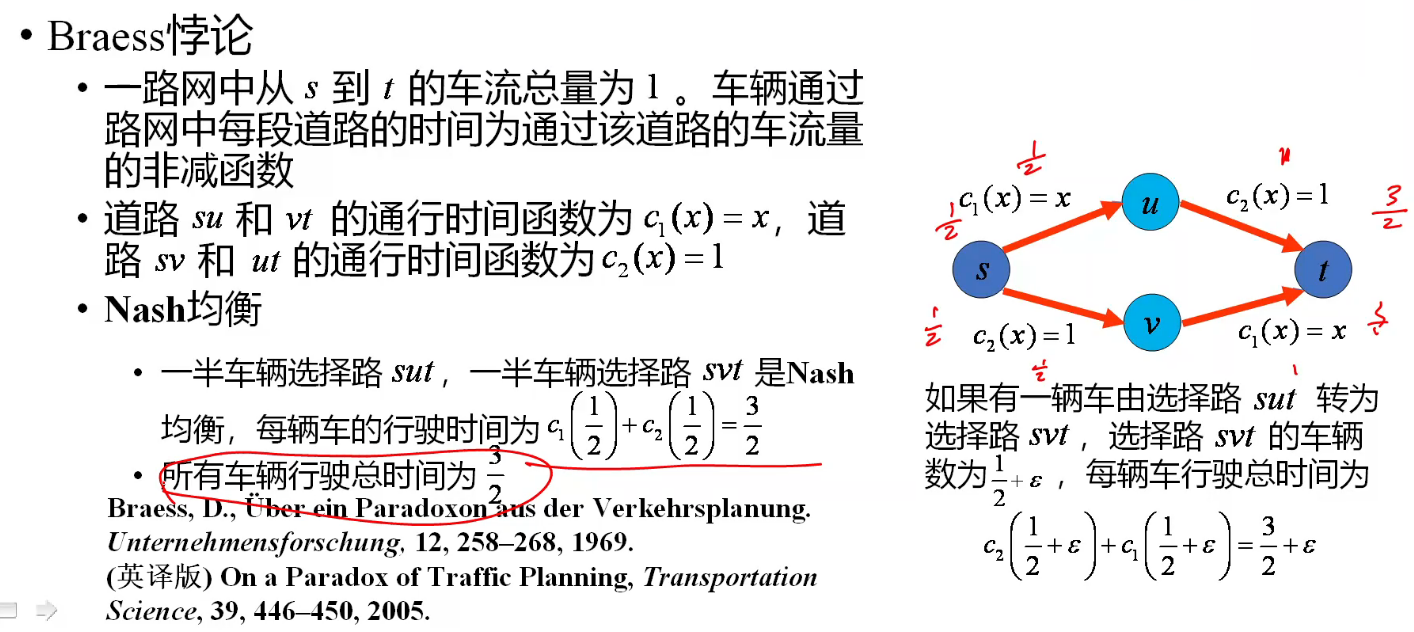

这体现出了 低效的均衡(inefficient of Equilibrium)
网络设计博弈

从单个使用者的利益来看,使用者 i 选择道路 si−t 是唯一的一个 Nash 均衡,总费用为 i=1∑ki1=O(lnk)
矩阵博弈
二人零和(zero-sum)有限博弈(完全信息静态博弈)
- 每人的可行策略集为有限集,设甲、乙的策略集分别为 {X1,X2,⋯,Xm} 和 {Y1,Y2,⋯,Yn},所有的局势形如 (Xi,Yj)
- 零和:甲的收益为 aij,乙的收益为 −aij
矩阵 A=(aij)m×n 称为博弈的收益矩阵
极小极大原则
若甲选择策略 Xi,不论乙如何选择,其收益至少为 1≤j≤nminaij。
甲的最佳策略是 1≤i≤mmax1≤j≤nminaij(每行最小值的最大值)
乙的最佳策略是 1≤j≤nmin1≤i≤mmaxaij(每列最大值的最小值)
可以证明 1≤i≤mmax1≤j≤nminaij≤1≤j≤nmin1≤i≤mmaxaij

如果 1≤i≤mmax1≤j≤nminaij=1≤j≤nmin1≤i≤mmaxaij,其为鞍点(saddle point)
- 若 ast 为鞍点,则 (Xs,Yt) 是博弈的 Nash 均衡
- 若鞍点不存在,则博弈不存在纯策略 Nash 均衡
- 例如石头剪刀布:01−1−1011−10 不存在鞍点,所以不存在纯策略 Nash 均衡
混合策略与期望收益

von Neumann 极小极大定理

数理经济学
Cournot 模型


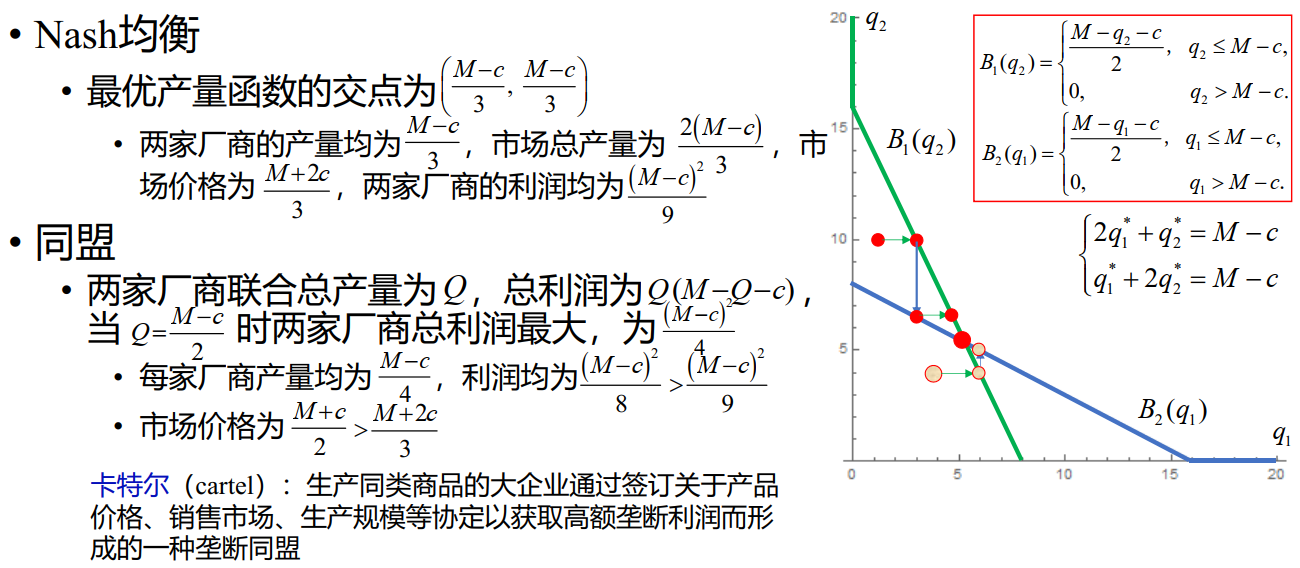
Stackelberg 模型

Cournot vs Stackelberg
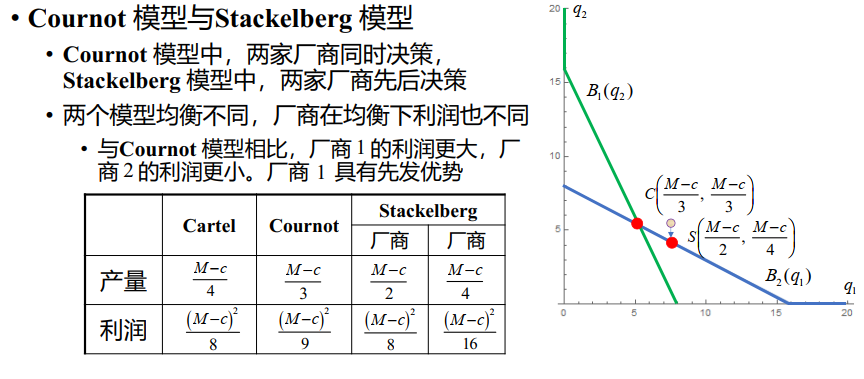
Bertrand 模型
Bertrand 认为 Cournot 模型中的假设不合理,因为他认为价格是市场的决定因素,而不是产量

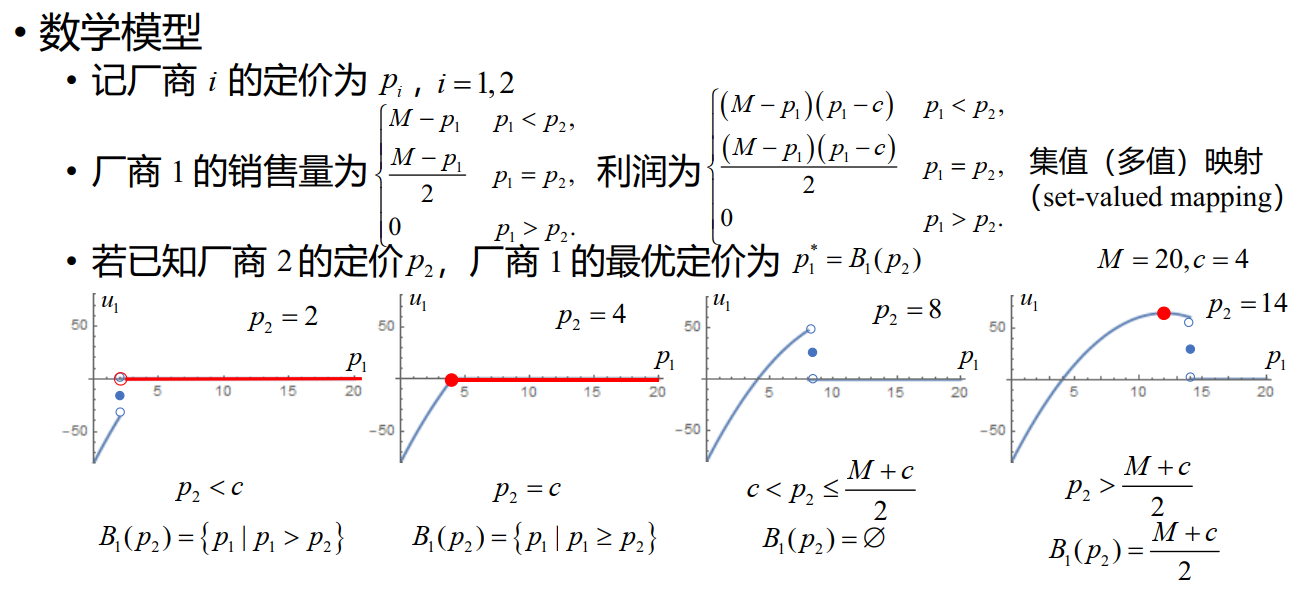
Cournot vs Bertrand
Cournot 模型与Bertrand 模型
- Bertrand 模型的均衡价格低于 Cournot 模型的均衡价格
- Cournot 模型以产量为策略变量, Bertrand 模型以价格为策略变量
- Cournot 模型与 Bertrand 模型基于不同的假设,适用于不同的市场环境,也存在各自的局限性
稳定婚姻问题

- 每位男士都选择他最钟爱的女士
- 如果有女士被两位或者以上的男士选择,则这几
位男士中除了她最喜欢的之外,对其他男士都表
示拒绝
- 被拒绝的那些男士转而考虑他(们)的除被拒绝
之外的最满意女士。如果存在冲突(包括和之前
选择某女士的男士发生冲突),则再由相应的女
士决定拒绝哪些男士
- 以上过程持续进行,直至不再出现冲突为止

推广 - 稳定室友问题

合作博弈
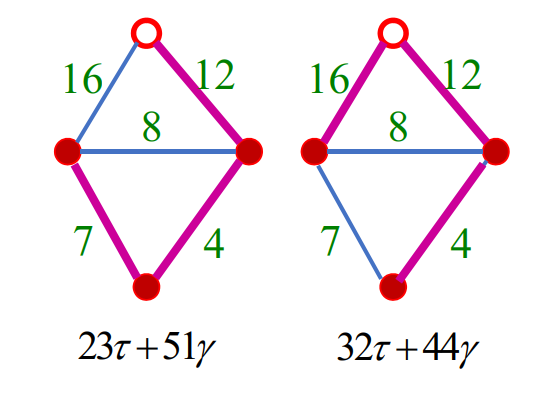
讨价还价
两人协商分配一笔总额为1万元的资金,约定如果达成协议,双方可以按协议取走各自应得的部分;若未达成协议,则两人分文不得,资金收归他用。




"证明存在唯一性"

"证明满足公理"

"最优解的性质"


破产清偿
两人 - CG问题 | Contested Garment
两人财产争议(CG问题)
- 甲方声称拥有某物品全部产权,乙方声称拥有该物品一半产权
- 双方对该物品的一半产权属于甲方均无异议,对另一半产权双方均认为属于自己
- 双方各获得争议部分产权的一半,无异议部分归属甲方
- 甲方获得该物品产权的四分之三,乙方获得四分之一
"推广"

右侧引入容器,两个容器中水平面等高,细管内忽略不计。可以以此列出各个情况。
n 人 - 破产清偿

CG性质:将任意两位债权人所得的还款额之和按CG问题的解重新分配,每位债权人所得的还款额保持不变
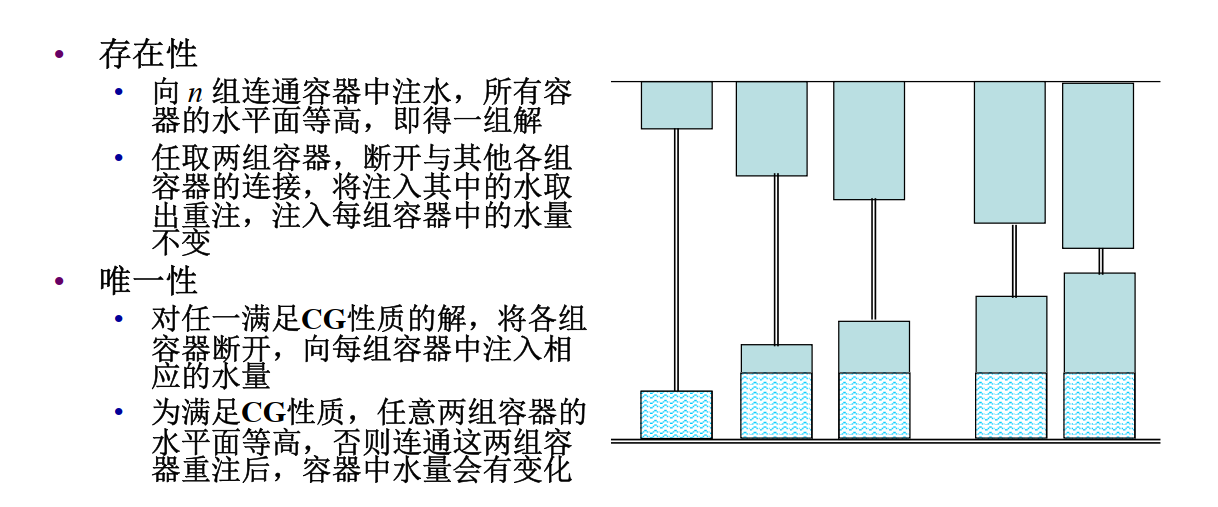
CG问题的解:两组连通容器中水平面等高
"存在性唯一性证明"
"存在性"
- 向 n 组连通容器中注水,所有容器的水平面等高,即得一组解
- 任取两组容器,断开与其他各组容器的连接,将注入其中的水取出重注,注入每组容器中的水量不变
"唯一性"
- 对任一满足CG性质的解,将各组容器断开,向每组容器中注入相应的水量
- 为满足CG性质,任意两组容器的水平面等高,否则连通这两组容器重注后,容器中水量会有变化
"情况枚举"